The Teracube 2e is a budget phone that promises to be more eco-friendly than your typical phone by committing to 3 years of updates as well as affordable repairs for 4 years (which is also the duration of the standard warranty), while also promising features and hardware that will remain relevant for that time. All of this for the low price of $199.
I've found that it generally lives up to its promises, but had to make several (and sometimes bizarre) compromises to get there.
I picked this up primarily to be a device I'm okay accidentally chucking in a river when I'm out traveling internationally, and can slot in a second sim for local data rates via a local SIM (though now that there are several eSIM options, I might do this with another phone in the future, particularly one with a better camera).
This is maddening! All of my chargers are basically PD ports, so I have to carry a whole separate cable just to charge the phone.
Verizon is not supported, and this includes all of their VMNOs. This is due to Verizon's certification process evidently.
I wanted to toss my V1 Ting card in there, and I had to use the X3 card instead - not a huge deal but did impact my plans.
There are a few reports on the forums of people getting Visible to work, but I've not been able to.
In a similar category, that I did realize before buying was that there's no IP rating, and so I wouldn't recommend trying to use this in a downpour or maybe any moist condition at all.
For a $200 USD phone, you really shouldn't be expecting much in the way of "great" but the 2e actually does an admirable job in several areas. The first thing that I like to call out is the display. It has a 720X1560 IPS HD+ display, which actually looks pretty great for the price point. The refresh rate is only 60hz, but asking anything more at this pricepoint is unreasonable.
The battery life on the 4,000 mAh battery is also quite good, I'm easily able to get a full day out of moderate usage - which is not something I can say for moderate usage of my primary phone. One of the other major selling points is the fact that the battery is replaceable, so you can pop off the back and swap it out if you need to, which should prolong the life of the device. Plus, there are settings which can prevent overcharging so you can tell the phone to only charge up to say, 80%, and then stop charging. Given the good battery life already, this isn't a big deal at all and should prolong the battery life even further.
The placement and the speed of the fingerprint sensor are a nice change of pace from the in-display sensors I've gotten accustomed to. It's been able to read my prints every time and unlock the phone quickly.
NFC Support! Which means it does work with Google Pay. I've not actually added any cards to it, but I have tested it as a general NFC reader and it works perfectly fine for that.
Dual Sim card support is another big draw, not too many phones have that. On the Samsung Note 20 Ultra you can use two sims, but then you give up the extra SD card storage - with the Teracube 2e, you don't have to choose, you get 2 sim slots and a microSD slot. It's wonderful.
Generally working custom ROM support is also on the Teracube forums, and the folks at Teracube are super cool with flashing custom ROMs to the phone.
The big stand-out problem here is the Camera. It's serviceable, but with the stock camera app it takes forever to focus on an item - HDR mode is so slow it's basically unusable for moving targets. I didn't expect much from the camera...but I expected more than whatever this is. Being able to snap photos on the go while traveling and get a semi-decent picture out (if I wanted it to be great I'd just carry my primary phone). Not being able to do this definitely makes me question using this as a travel phone.
Likewise, the processor is a little sluggish at odd times. In general, performance is reasonably good and on par with the Moto Play line of phones, but sometimes it'll chug just a little - enough to miss a letter while typing or just stuttery enough to be annoying but not super disruptive. I expect this will get better after some updates or via a custom ROM - but it does make me wonder how the phone will handle Android 11 or 12. This phone's supposed to get updates for 3 years, remember?
So, if you're getting this phone you shouldn't expect that you'll be able to play modern phone games - but it can be nice to sit down and play something if it's the only device you've got.
The short answer is that any modern 3d game is going to have a really hard time, with some interesting exceptions. I've tried the following games and can report on how well they work:
Totally unplayable - the framerate is bad enough that gameplay is impossible. You can manage your inventory and collect daily things, but it won't be a fun experience.
Battlechasers: Night War
Mostly Unplayable - it stutters a lot when you try to move around the map.
Black Desert Mobile
Borderline - So this game is a weird one in that the performance is adequate, and you could play it if you really really wanted to... but the quality level is potato. It's going to be blurry. This is probably fine if you just want to hop on, sell some stuff, do dailies, etc - but I wouldn't want to be playing it for any length of time.
Reasonably Playable - this surprised me, I managed to play a full match at a solid 30 fps without any noticeable slow down when I was in the game. Load times are noticably slower though, so you might be the last person to fully load the game, but otherwise it works just fine.
Love Letter; One Deck Dungeon; Reigns
Plays great - these are basically digital card games, and they play really well on the device.
Out There Omega
Plays well - a little slow at points, but all in all it runs great
Game Dev Tycoon
Plays great - I'm pretty sure this game could run on a literal potato, but it does do just fine.
Doors: Awakening
Mostly Playable - This is a nice little puzzle game, and it generally works fine but the load times are noticably slow and sometimes interactions are slow.
Polytopia
Extremely Playable - It's a nice little civ-like mini game. No issues, runs very well.
At the time of this writing, out of the box you cannot install apps to the SD card. You have to first enable developer settings () and then turn on the option to enable it. Afterwards, it works just fine. It'd be nice if it were in the stock image and maybe it will be after their first upgrade.
Use a different camera app. It doesn't make the camera much better, but it does speed up how quickly the auto-focus takes effect. The forums recommend Open Camera, which seems to be working fine for me (even though I kinda hate the UI).
So bottom line, I got this as a secondary phone - not to be my daily driver and I do not think it would be a good daily driver for me. I'd probably survive but I wouldn't enjoy it, especially since I like playing some fairly intensive games on the go or from the couch.
That said, if you're the kind of person who is already considering something like a Moto G line phone, or one of the budget Samsung Phones (like an A52) - and you don't need a serviceable camera, this is a solid contender at a price point that's difficult to beat. Once you consider the warranty, the accidental damage repairs, and the promise of a more eco-friendly phone that might just push you over the top.
I've made a new review about the Asus ROG Ally over in the reviews section, but due to an artifact of how I set up the RSS feed, you won't know about it unless I make a stub here. So! Here's the stub.
Okay. Maybe I have a bit of a handheld gaming problem. See, when we last talked about this, one of the key things that I outlined as a requirement for my gaming handheld was the ability to connect an external GPU to the thing so that I could play it on a desktop with decent performance.
While I could eventually do that with the Ayaneo 2, the process was extremely fiddly and prone to breaking any time there was a software update. Likewise, you had to plug the eGPU in during a particular part of the boot sequence so that it would properly detect and use the eGPU. Related problem: if you allowed the system to go to sleep, it would not properly function when it awoke, requiring you to force restart the machine and do the little plug-it-in-ritual all over again. It was extremely frustrating.
So, doing the thing that I seem to always do, I went completely overboard and looked for a different solution. When Asus decided to put out their own handheld, complete with a mobile eGPU solution (which uses laptop graphics cards - we’ll get to that in a minute), I decided that was the way to go. I purchased the Rog Ally Extreme at launch (which, at the time, did not contain the “extreme” moniker - that came later when Asus made a less-performant but cheaper model) along with one of their XG Mobile eGPUs (the 3080 version). The price was eye-watering, and for the eGPU - overpriced. What it promised, however, was a better eGPU experience, and I was willing to pay a premium if that worked. More on that later.
The Handheld Experience compared to my other handhelds
On the whole, the Ally is a great experience as a handheld. The actual comfort of the device while it is in use ranks #2 out of my entire collection, just behind the Steam Deck. It’s really comfortable to use for extended periods of time (in my hands, which are rather…large), and it even has back paddle buttons which you can remap to do what you want with them.
The screen is also a delight - it has a 120hz refresh rate, which you’ll be hard-pressed to actually hit on anything but retro or indie games, that has a nice color quality to it for an LCD. Asus’s software support also has several visual tweaks you can apply to make the colors more vivid, should you desire that. It also is a 1080p display, which is just much better than the Steam Deck, and just behind the 1200p of the Ayaneo 2. It’s not as vivid as the OLED on the Ayaneo Air, but it’s probably my favorite screen of the bunch.
Sidebar: The Ayaneos both use displays with a native resolution that is vertical and then uses software to make the image horizontal - this causes an issue in some games, notably Phasmaphobia, where the resolutions only appear in the vertical orientation.
Performance-wise, it’s definitely more capable than the Steam Deck for sure. There are a ton of reviews out there that actually crunch the number, but my “feels” test for undocked performance, in 15W and 30W power profiles, is that the Ally is the most capable device I possess. The second place goes to the Ayaneo 2, but it still struggles with other games with the previous gen Ryzen processor.
The size is a bit wider than my Ayaneo 2, but smaller than the steam deck overall, so it’s really the perfect size for couch gaming - I still default to the Ayaneo Air for travel though, it’s really hard to beat its size profile. If you want to see a comparison Rock Paper Shotgun has several comparison photos.
Overall: This is the device I pick up most often, both when playing on the couch and when playing docked.
Remember earlier how I said Asus promised a better docked experience than the Ayaneo 2? Well, that only partially materialized. For one thing, when you plug in the XG Mobile, it recognizes that you’ve done so, and it prompts you to switch the graphics driver from the internal to the external - giving you a prompt to restart the programs in question. So far, so good.
That works about 80% of the time now (when I first got it, it was maybe 60% of the time, so hey, improvement!). When it doesn’t work, you either have to run the script several times to try to get it to stick - or you need to reboot the device and try it again. So while I’m happy that I don’t have to do the little cable dance ritual anymore, I still have to deal with a non-functional script sometimes.
Likewise, this combo also has the problem where if it doesn’t output to the screen for a while (either by falling asleep or you switching monitor inputs), it will refuse to display on that screen again until you suspend / resume it. That’s better than a full reboot by far, but it’s still annoying. For a laptop eGPU that cost nearly $1500 at the time of purchase, I feel like the experience should be better.
Maybe I’m being nitpicky here, but that’s a premium price and I don’t think it’s super unreasonable to expect a premium experience. To Asus’s credit though, it’s been getting steadily better with software updates, so maybe it’ll get to that coveted 99% (nothing ever works 100% of the time with computers).
After a couple of months with the stock drive, I upgraded the SSD inside of the Ally from the 512 GB it came with to a 1 TB SSD, and the actual installation process was a breeze. The case was simple to get open, and the SSD was readily accessible without having to move anything out of the way. Asus has also produced a handy guide that covers the process. It’s a snap.
I chose to reinstall the OS instead of copying the old SSD over, and … that was a bit of a process. On the good side, Asus includes a utility in the BIOS to re-flash the SSD with everything you need, Windows included. On the bad side, when I did it, my version of the BIOS had a bug that messed up the system clock, so I had to search around the internet until I found a post detailing that fact. The fix was simple: Set the system time to an accurate time yourself, and then you can proceed. HOWEVER! Even with that fix, I had to attempt this install a grand total of 4 times before I got a functional Windows install. It did eventually work, but it was several hours’ worth of “try, wait, and try again”.
It took them a while, but Asus did finally admit that the ROG Ally has an appetite for eating delicious SD cards, metaphorically at least. Apparently, the card reader gets a little too hot during operation and that can cause it to malfunction and completely break the SD card inside.
While I’m happy to report my unit has not destroyed any SD cards yet, the write speed on it is atrocious. Takes absolutely forever to install anything but the smallest games. As a result, I barely use it for anything that’s not tiny. Which is a shame, since I have filled up the SSD a few times now and have to regularly prune games in order to keep relevant stuff installed. Either that or resort to game streaming. Glad I have a good internet connection.
Look, I really like the ROG Ally - it’s become my daily driver. I even wound up giving the Steam Deck to a friend, despite it having the vastly superior control scheme. Perhaps I’d be happier with the Steam OLED’s upgraded display, but I don’t feel compelled to spend any more money when the Ally fits my needs for the most part. The fact that I dropped $2000 on it all told has also made me more fond of keeping it alive and relevant for as long as possible.
That said, the handheld gaming scene keeps evolving - who knows what we’ll see in the next couple of years.
The other day, a friend asked me a complicated question wrapped in what seems like a simple question: “How long would it take to make some simple mini-games that you could slap on a web page?”
My answer, as many seasoned developers will be familiar with (and of course it’s coming out of the architect’s mouth) was “It depends on the game and the developer. I could probably churn out something pretty good in a few days, but it’d take someone more junior longer”.
This set off the part of my brain that really wants to test out just how fast I could do a simple game in engines that I’m not familiar with. Thus, I decided to ignore my other responsibilities and do that instead! Mostly kidding about the responsibilities thing, I’m ahead of my writing goals for Nix Noctis, so I had a couple of hours to spare (and a free evening).
How long would it take to make a simple “Simon” game in GDevelop: a “no code” game engine? I wanted to start with GDevelop for a few reasons:
I wanted to simulate the experience someone with little coding experience would encounter. Knowing that I’ve internalized some concepts that would make the experience easier (or, in some cases, harder) for me.
You can run the editor in a web browser, and that’s bonkers.
I want to “pretend” to be a beginner; only use basic and easily searchable features.
I mean, I am a beginner at game dev, but I do understand several the concepts.
With those things in mind, I set out to remake Simon. Here were my design constraints:
Four Arrows, controllable by clicking them or via the keyboard.
Configurable number of “beeps” in the sequence
The game would not increase by one each time (though it easily could)
Three Difficulty levels which control the speed that the sequence is shown
REMEMBER! I’m a beginner at GDevelop. You’re likely going to see something and say “hey that’s dumb, you should have done it another way”. Yes. Exactly.
The editor experience in GDevelop is actually really nice, especially when you can just get into it via clicking into a browser. I found adding elements to the page very intuitive. Sprites are simple, and adding animation states to them is effortless. Creating the overall UI took me probably 20 to 30 minutes to iteratively build out a structure I was happy with, it was fast. Another fun thing I discovered was that they have [JFXR] built into the editor, and that was a delight.
What was not so quick was wiring up the game logic to the elements on the page. I’ve looked at some GDevelop tutorials before, and if you’re treading a path that’s covered by one of their “Extensions”, you’re going to have a great time. A 2D platformer will be a breeze because you can simply attach a behavior to the sprites in your game and go. There are a bunch of tutorials on making a parallax background for really cool looking level design. Simple!
What is not so simple is if you fall outside those behaviors and need to start interacting with the “no code” editor. On one hand, the no code editor is nice! The events and conditionals are intuitive if you’re approaching it in certain ways. They even let you add JS directly if you know what you’re doing (though they recommend against it). On the other hand, I can see this getting quickly messy. In my limited experience with the engine, I could not find a good way to reuse code blocks. This will come up later.
Sidebar, dear reader, I believe this is where they would say “you should make a custom behavior to control this”. I’m not sure a beginner would think to do this, but I thought about it and said, “I’ll just duplicate the blocks”.
As I worked through this process, I ran into a number of weird stumbling blocks that slowed down my progress while I tried different things.
Were I making this game in pure JS, generating the sequence would be a pretty “simple” one-liner (It’s not that simple, but hey, spread operator + map is fun! I’d expand this in a real program to be easier to understand):
// Fill a new array of size number_of_beeps with a digit between 0 and 3 to represent arrow directions let sequence =[...Array(number_of_beeps)].map(()=> Math.floor(Math.random()*4));
Generating the sequence was remarkably easy once I figured out how to do loops in GDevelop; they’re hidden in a right-click menu (or an interface item), but the “Repeat x Times” condition is precisely what we needed.
Likewise, doing the animation of the arrows was pretty direct. All you need to do is change the animation of the arrow, use a “wait” command, and then turn it back. Easy!
Turns out it’s not actually that easy. The engine (as near as I can tell) is using timeouts under the hood which means they’re not fully blocking execution of other tasks in sibling blocks while this is happening. Which means…
Okay, so when you’re playing Simon, the device will beep at you, light up for a non-zero number of seconds, and then dim. It should do that for each light. If you’ve never experienced this wonder of my childhood, watch this explanatory video from a random store:
Now that we know how that works, we want to emulate that in GDevelop. The first thing I tried was to simply put the “Wait” block at the end of a For...In Loop. Yeah, remember what I said about timeouts? Those don’t block. The loop would just continue and totally ignore the wait. I think that’s a major pitfall for new devs, they’re not going to understand the nuance of how those wait commands function under the hood.
The second thing I tried is the “Repeat Every X Seconds” extension to do the same thing. I couldn’t get it to even fire, and I still don’t know why.
Anyhow, I settled on using a timer to do the dirty work. Here’s how our “Play the sequence loop” wound up looking at the end:
Conditionals / Keyboard Input Combined with Mouse Clicks
There’s another thing I could not figure out. I wanted to have both mouse clicks and keyboard input control the “guess” portion of the code, so I sensibly (imo) attempted to combine those into a single conditional. That wound up being…very weird, and there’s still a bug related to it.
First off, there are AND and OR conditionals. It took me a bit to find them, but they do exist. So, with a single OR conditional and a nested AND conditional, I set out with this:
This mostly works. However, for whatever reason, if you use the keyboard to input your guess, the arrow animation does not play. I do not know why. It works if you click. I can prove the conditional triggers in either case. It’s just that the animation does. Not. Work. Maybe one day I’ll figure it out, but I chose not to.
Struggling past some of those hurdles, it took me about 5 hours to meet my original design goals in GDevelop. Not terrible for not knowing anything about GDevelop besides that it exists.
After I’d done the initial experiment, I was curious if I could work faster in a game engine that has real scripting support.
The short answer is “yes”. It took me about 2.5 hours to complete the same task in Godot (with some visual discrepancies). I think the primary speed gain was from the fact that the actual game logic was much more intuitive to me and the ability to wire up “signals” from one element to the main script code made it much faster to do some of the tasks I was fighting in GDevelop.
Godot also has an await keyword which blocks execution like you’d expect it to, which is outstanding.
I did run into one major issue that I had to do a fair amount of research to solve:
AnimatedSprite2D “click” tracking is surprisingly difficult
The only issue I had was that when I needed to determine if the user had clicked on an arrow, I had to jump through some interesting hoops to detect if the mouse was over the arrow’s bounding box.
While regular sprites have a helper function get_rect() which allow you to figure out its Rect2D dimensions, AnimatedSprite2Dvery much do not (you have to first dig into the animations property, and then grab the frame it’s currently on, and then you have to get its coordinates and make your ownRect2D. Gosh, I’d have loved a helper function there).
I think the expectation is you’d have a KinematicBody2D wrapping the element, but as the arrows are essentially UI, that didn’t make any sense to me. I’ll need to dig a bit further into how Godot expects you to build a UI to do all of that, but hey, I got it working relatively quickly.
Changing the text of everything in the scene was really bizarre due to how it’s abstracted via a “Theme” object that you attach to all the UI elements? Still haven’t quite figured that out. It was really easy in GDevelop. Not so much in Godot.
Yeah, so, I liked working in Godot more because it was easier to make the behaviors work, and I was getting exhausted at the clunkiness of the visual editor. Here’s the final product:
For me, working in both of these engines for fun was a positive experience and I can see myself using GDevelop for some quick prototyping, but personally, I like Godot’s approach to the actual scripting portions of the engine. Because I have a lot of software development experience, it’s much easier for me to just write a few lines of code over having to navigate the quirks of the interface.
I think GDevelop is perfectly serviceable, though. It looks like everything in the engine does have a JS equivalent, so you really could just write JS if you wanted to. If they exposed that more cleanly, I think it’d be pretty great for many 2D needs.
But I’m not a game dev, this is just me tinkering around and giving some impressions. Go try them out for yourself, they’re both easy to get started with!
Not too long ago Anil Dash wrote a piece for Rolling Stone titled “The Internet Is About To Get Weird Again” and it’s been living rent free in my mind ever since I read it. As the weeks drag on, more and more content is being slurped up by the big tech companies in their ever-growing thirst for human created and curated content to feed generative AI systems. Automattic recently announced that they’re entering deals to pump content from Tumblr and Wordpress.com to OpenAI. Reddit, too, has entered into a deal with Google. If you want a startling list, go have a look at Vox’s article on the subject. Almost every single one of these deals is “opt-out” rather than “opt-in” because they are counting on people to not opt-out, and they know that the percentage of users who would opt-in without some sort of compensation is minimal.
Lest you think this is a rant about feeding the AI hype machine, it’s not (though you may get one of those soon enough). This is more of a lament from the last several decades of big social medial companies first convincing us that they are the best way to reach and maintain an audience (by being the intermediary) and then taking the content that countless creators have written for them and then disconnecting the creator from their audience.
Every bit of content you’ve created on these platforms, whether it’s a comment or a blog post for your friends or audience is being monetized without offering you anything in return (except the privilege of feeding the social media company, I guess). Even worse, getting your stuff back out of some of these platforms is becoming increasingly difficult. I’ve seen many of my communities move entirely to Discord, using their forums feature. However, unlike traditional website forums you cannot get your forums back out of Discord. There’s no way to backup or restore that content.
I’ve personally witnessed a community lose all of its backup content due to a leaked token and an upset spammer. It was tragic and I still mourn (but hey, we’re still there).
In one way, this is the culmination of monetizing views. As Ed Citron argues in Software has Eaten the Media, the trend from many of these social media companies has been “more views good, content doesn’t matter”. We’ve seen this show before, Google has been in a shadow war with SEO optimizers for over a decade, and they might have lost. The “pivot to video” Facebook pushed was a massive lie, and we collectively fell for it.
So what do we do about this? One thing I’m excited to see that Mr. Dash rightly points out is that there’s a renewed trend of being more directly connected to the folks that are consuming your content.
Own a blog! Link to it! Block AI bots from reading it if you’re so inclined. Use social media to link to it! Don’t write your screed directly on LinkedIn - Don’t give them that content. Own it. Do what you want to with it. Monetize it however you want, or not at all! Own it. Scott Hanselman said this well over a decade ago. Own it!
Recently, there was a Substack Exodus after they were caught gleefully profiting off of literal Nazis. Many folks decided to go to self-hosted Ghost instead of letting another company control the decision making. Molly White of Citation Needed (who does a lovely recap of Crypto nonsense) even wrote about how she did it. Wresting control away from centralized stacks and back to the web of the 90s is definitely my jam.
Speaking of Decentralization, we’ve also got Mastodon and Bluesky that have federation protocols (Bluesky just opened up AT to beta, which is pretty cool) allowing you to run your own single-user account instances but still interact with an audience (which is what I do).
Right, anyhow, this rant is brought to you by the hope that we’re standing on the edge of reclaiming some of what the weird web lost to social media companies of yore.
I’ve searched long and hard for the perfect writing tablet for me, and I’ve found it in Supernote. It’s the perfect blend of “write-on-able”, readability, and features. It often features in blog posts over on Cthonic Studios because it also makes it super easy to make character sheets, do some quick doodles, and has several nice features.
But, I want to spend a bit of time talking about the other things I’ve tried and wound up walking away from (I’ve provided Amazon Affiliate links for convenience if you happen to want one of these alternatives, meaning I’ll get a small commission should you choose to buy something).
It’s worth noting that I am primarily approaching this from an “Is the writing experience good first, followed by the reading experience, followed by the extra features” so that’s the criteria I’m judging.
Other bit: I purchased all of these, no one is paying me to write about them.
All of these options support Templates and Layers for their notebooks, to varying degrees — these let you set custom backgrounds on your documents, so you can have more than just the basic lines / dots / etc. Where they lack in features, I’ll call out.
Most of the devices also have a “paper-like” feel to them, except for the Kobo Sage.
Basically, any eInk device is going to have issues with image-heavy PDFs, which I tried on all of them, but haven’t really had a great experience.
My first foray into having a dedicated tablet for writing actually started as an attempt to get my wife something that was useful for marking up PDFs. At the time, her job involved a lot of scientific paper review, and she needed something that would be easy on her eyes but transfer the markup. The Scribe was on a very deep discount at the time, and it promised document markup, so we decided to give it a shot.
Reader’s sidebar: this became a moot point as organizational policy prevented her from actually using the device, but hey, we don’t create eWaste in this household willy-nilly.
Dear reader, the PDF markup capabilities of the Kindle Scribe leave a lot to be desired. You can only annotate PDFs that you have sent to your scribe via their Email conversion service, not via side-loading them by USB cable. I don’t really want to hassle with sending things through Amazon’s servers just to enable annotation, so this was a hard stop for the both of us. You see, I also like to annotate PDFs to review stuff I’m working on, for unpublished games / adventures and I don’t want that going through Amazon’s servers either.
The annotation problem also extends to Kindle books, only certain Kindle books in a particular format allow for direct annotation. Many of them default to the old kindle style annotation where you highlight a passage, and then you can make a text/handwriting annotation on that text. That’s way more annoying than just writing on the text. There is a growing body of Kindle books that are directly annotatable (along with several puzzle books you can buy), but the selection is still fairly small at the time I’m posting this.
The writing experience itself is actually fantastic, the pen feels nice on the device, and it feels pretty close to writing on paper. The input delay is minimal, I don’t really notice it. There are a pretty solid set of marker shapes and sizes to choose from, though switching between them takes a bit of time (this will be a common theme, throughout).
I appreciate the inputs on the pen. It features a side button which defaults to the highlighter and an “eraser” on the back, much like a real pencil. It feels pleasant in the hand, though if you’ve got wide hands like me, it’s going to feel a little small.
There’s not a dedicated template feature on the Kindle Scribe, you have to make a PDF with your template and then annotate the PDF directly. Annoying, but it works.
The one complaint I have about the pen is the need to replace the nibs periodically. The Supernote features a pen that has a permanent tip (the film on the device is self-healing so they can make the nib harder), but in practice I only changed the nib on the Kindle once.
Accessing your notebooks from other devices is a bit of a crapshoot. You used to be able to view them online via a specialized link (which as far as I can tell, they never advertised), but they removed that link.
You can access those notebooks via the Kindle mobile app in read-only mode. That’s about the only sync option you’ve got.
This is about what you’d expect from a Kindle in 2024, the screen is clear and crisp. There’s a backlight. It can do cold and warm lighting with a bunch of adjustable brightness. This is impressive because one of Supernote’s core claims about why they do not have a backlight is because it would degrade the writing experience. Maybe a little, but for me, I can’t really tell (and kind of wish the Supernote had a backlight).
The biggest obvious advantage here is that if you’re already in the Kindle ecosystem and have given Amazon piles of money for books, you can easily access your library on the device because at its core it’s just a Kindle.
You can also still side-load DRM free eBooks in various formats. Picture-heavy PDFs still have some performance problems, an issue I’ve seen with other eReaders.
The Scribe is probably my second favorite of the tablets I’ll be talking about today, and also generally, the easiest to acquire. For me, it’s more of a “reading tablet that happens to have writing capabilities” (See also the Kobo Sage)—and while its writing experience is workable, it’s not ideal.
Its current price is $419 USD for the 64 GB model with the premium pen included, though it’s frequently on sale. You can also pick up a refurbished model for as low as $309.
The second tablet we tried after finding out about the PDF limitations on the Scribe was the Remarkable 2, which was a fair amount pricier but hey, at least it supports PDF annotation via side-loading out of the box.
Like the Kindle, you can transfer files over USB. It does this via an embedded web server and specialized website that’s served over an IP address over the USB interface. It’s a little weird, I expected it to mount a drive like the Kindle does.
Remarkable has the Remarkable Cloud Service which allows you to sync notebooks between your devices via their cloud, as well as offering Google Drive, Dropbox, and OneDrive integrations. This allows you to sync your stuff to different clouds even without the subscription. There is a cost associated with Remarkable Cloud Service.
Finally, you can sync files via the Remarkable apps available on mobile and desktop over Wi-Fi.
The Remarkable 2 Writing experience is quite nice as well, it feels like you’re writing on paper. I went back and forth between the Remarkable and Scribe when we first got both of them (right around the same time, as you might recall) and it was difficult to determine a clear winner between the two when it comes to writing experience and accuracy.
The Remarkable suffers from the same problem as the Kindle, switching between pen types requires a few taps each time you want to do it. That slows me down a touch when I’m taking notes and want to call out stuff like headers. Like the Kindle, there are many pen types to choose from and switch between.
The pen is also fairly nice (we have the Marker Plus pen, but there is also a “basic” pen), but compared to the Kindle and Supernote Pens, I have two major complaints:
The eraser side requires more pressure than I would like to use
There’s no highlighter button (which is also a thing with the Supernote pen)
Likewise, the pen nibs are intended to be replaced on the Remarkable, and we tend to go through them quickly. There’s also a very fun quirk if the pen tip gets too worn down, it will start to write when the pen is not in contact with the Remarkable. On the one hand, great visual indicator that you need to replace the nib. On the other, pretty annoying if it starts happening when you’re not anywhere near your replacement pen nibs.
Remarkable also has a Keyboard Folio which allows you to type notes directly, but I’ve never used it, so I cannot comment on the experience.
Your basic options are the same as the Kindle Scribe. You can either export as a PDF or you can convert it to text first. The difference here is how you get it to other devices. You can:
The reading experience is pretty good, but not as convenient as the Kindle.
There are no built-in services to connect to, so you have to transfer your eBooks manually via any of the mechanisms mentioned above. It can handle reading PDFs very well, but like other eInk devices, it struggles with image-heavy PDFs.
The ePub experience is pretty good, it provides a few different ways to navigate the content, either via a full page view or via the quick browse feature they recently added.
There is no backlight, so you will want to have a suitably lit environment if you intend to read eBooks on the Remarkable 2.
Compared to the Kindle, this is a tablet that was designed for writing first, and reading second. The writing experience overall is better, especially when it comes to getting your content from the device. I, personally, don’t want everything going through anyone else’s servers, and Remarkable makes that possible.
It also comes in at a fair amount pricier than the Kindle Scribe, at $549 for the bundle with the cover and Marker Plus pen.
Who in this house needs better control over the lighting in here? It's me!
I wanted to like the Sage. I really did. A while ago, I stopped buying books through Kindle and instead started borrowing more books from my local library and when I couldn’t do that, getting them through Kobo. So, I have a fair amount of content in the Kobo Ecosystem now.
The Sage + Pen combo was one of my first forays into the “can I go paperless” experiment, well before the Remarkable 2 and Scribe experiments (before the Scribe existed, even). The major thing I liked about it is the size. It’s compact and easy to carry around. If I could read on it and scribble some notes, all the better.
The battery life isn’t nearly as good as I’d expect from an eReader, which is probably why Kobo sells a special case that charges the device, but it’s not terrible.
I still use it for reading, but after giving it several shots, I’ve not used it for writing again.
The first problem with the writing experience is that the surface of the device is not grippy like the other devices in this list. The pen does not counter this in the slightest, so when you write the nib slides around a lot more than I would like. It’s very similar to the iPad pencil tips in that regard. Some people are okay with this, but I want my writing experience to feel more paper-like.
The second is sometimes it doesn’t register the pen strokes. Lines will wind up broken, drawings look weird. I think this also has something to do with how the Sage’s case functions with magnets. I’ve discovered that if you try to write when the Sage is in contact with metal, like my back porch’s table, it gets much worse. Dunno why that is, but it makes it basically unusable.
There is some noticeable lag between drawing a line and it appearing on the screen, and occasionally, it’ll just write before you tap. Yeah. Not great.
The stylus is “fine” (I have the original stylus, not the 2) but it rattles as you’re using it, so I didn’t really like using it. It has two buttons on the side, one for erasing, one for highlighting.
Notebooks come in two styles: Basic and Advanced. Advanced notebooks use Nebo under the hood, and it behaves basically exactly like that app. You can make nice diagrams, move things around, and numerous other things. Nebo’s also available on Android and iOS if you want to give it a shot there.
Compared to the writing experience, the reading experience is good! Like modern Kindles, there is a good backlight with an adjustable temperature for warm and cold light. The device is pretty snappy, and you can side-load other eBooks onto the device.
Furthermore, like the Kindle, there are integrations with OverDrive for loading library books and finding them directly from the device.
Like other eReaders, it struggles with image-heavy PDFs.
Much like the Kindle Scribe, this device was built for reading first, and writing second. Unlike the Kindle Scribe, that is a very distant second. For me, it’s borderline unusable.
The Sage is the cheapest option on this list is $270 without the pen. The stylus costs an additional $36.
Okay! I’ve saved my favorites for last. I like this device so much that I’ve actually got two of them. Not only that, but I picked up the A5X near the end of its lifecycle, and the Nomad as soon as it came out.
Of the devices we’re looking at today, this one has the most flexibility when it comes to getting content onto it. It’s running Android under the hood (though it’s way more locked down than something like an Onyx Boox), so you can also mount the filesystem via a program like OpenMTP to transfer files back and forth. I have had an issue on newer macs where the “Allow USB connection dialog” disappears too quickly to allow the Supernote to connect, however. Still not sure what’s up with that. This only happens on the Nomad, not the A5X.
It also has a nice feature where you can turn on the ability to transfer files over Wi-Fi. Turning on that feature starts up a web server on the device, allowing you to drop files on it. The downside to this is that it starts a web server on the device, which is discoverable on the network. I’d only do this at home or on other networks you control / trust. Don’t do it on public Wi-Fi unless you want someone doing shenanigans.
They also allow you to sync files back and forth via Dropbox, Google Drive, OneDrive, or Supernote Cloud as well as a companion Mobile app that works over Wi-Fi.
Like the Remarkable 2, it has the option to connect a keyboard; this time you can use any bluetooth keyboard you’ve got lying around. That’s a cool feature, but the refresh time makes the typing experience suboptimal. If you can put up with a little input lag, it’s not terrible.
Small sidebar, the way the Nomad attaches to its case via magnets is A+, love it.
Unsurprisingly, for me, the Supernote is the best writing experience of the bunch. It feels the closest to paper for me, and it has some convenience functions that make it much quicker to do certain kinds of writing.
One of the things you might have noticed that I mention on basically all the prior devices: Switching between pens is kinda slow and awkward. Supernote solves this problem by letting you set custom hotkeys on the sidebar so that you can rapidly switch between the kinds of pens you use rapidly.
There are also a number of multi-tap and sidebar gestures for undo, redo, change the toolbar, and the like. It’s really solidly done.
The other thing I really appreciate is the ease of using custom Templates. You can use both imagesandPDFs and then easily set those as a background. Here’s an example of me using the Ironsworn Character Sheet PDF as a background:
The only negative I’ve had with the Nomad (which does not happen on the A5X I think) is that sometimes tapping the pen will not produce a dot, making it so that I have to be careful to properly dot i and j.
I have the premium Heart of Metal 2 Pens, which feature the ceramic nib that never needs to be replaced (which is awesome). It doesn’t feature any buttons, but the gesture controls make that almost unnecessary (but it would be nice). There is a secondary pen option which has a side button that activates either the lasso or eraser lasso tool.
The Supernote gives you the ability to export in PNG, PDF, TXT, and .docx formats, and it lets you sync via any mechanism you can use to get content on the device (so, USB, Supernote Cloud, Google Drive, Dropbox, OneDrive, over Wi-Fi).
Additionally, it has the ability to “Share via QR Code” which uploads the note to Supernote and generates a URL that is good for 24 hours, where you can download the note via a web browser.
Likewise, the reading experience is almost perfect. As I mentioned above, there is no backlight, which I sometimes miss. It supports all the usual suspect formats, including PDFs. They’ve got strong enough processors that RPG pdfs do tend to work okay. They still struggle with the image heavy ones (which is sadly most Pathfinder adventure paths).
Because this is an Android-based device, you also have some access to Android apps. The “Supernote Store” on the devices allows you to install the Kindle app, providing you with access to your entire Kindle Library. It’s possible to side load applications on it if you can access the debugger, but I’ve not personally done so. As of the latest updates for the Nomad, they’ve added a “side-loading” button which enables debugging. I’d love to add the Kobo app, but I’ve not attempted to do so yet.
Otherwise, there’s not much else to say — navigating around books and PDFs is quite pleasant, and it’s got a nice feature for PDF bookmarks, letting you skip around the bookmarks quickly rather than having to scroll through them.
This is my favorite eInk writing tablet I own, so much so that I bought it in two different sizes.
Believe it or not, the Nomad is not the most expensive item on this list (nor was the A5X!) by itself. The device clocks in at $299, but when you start adding accessories, it adds up. The Heart of Metal 2 Pen is $75, the folio is $49, so a full package is $423, just over the Scribe’s price (even more if you get a refurbished one or grab it when they do periodic Kindle sales).
I’ve tried to do some writing on my iPad, and it works out reasonably well, but the default pen tips suffer from the same problem of sliding around and not feeling good to write with. I have tried the Pentips 2+, but they are egregiously expensive, and I’ve had some quality control issues with them. I’m still rocking one of those for doing drawing / creating the OSRaon Icon Set, but it’s not great for writing.
Boox makes a ton of eInk tablets that are running “Basically stock Android”, which is wild to me. I’ve been debating picking one up. They have color eInk variants too, in various sizes. I’m a little worried that the writing experience won’t be great, but the temptation is strong.
If I wind up doing so, I’ll post a follow-up review.
Also known as the “Plausible Sentence Generator” and “Art Approximator”
This post is only about Generative AI. There are plenty of other Machine Learning models, and some of them are really useful, we’re not talking about those today.
I feel like every single day I see some new startup or post about how Generative AI is the future of everything and how we’re right on the cusp of Artificial General Intelligence (AGI) and soon everything from writing to art to music to making pop tarts will be controlled by this amazing new technology.
In other words, this is the biggest tech hype cycle I’ve personally witnessed. Blockchain, NFTs, and the like come close (remember companies adding “blockchain” to their products just to get investment in the last bubble?) and maybe the dotcom bubble, but I think this “AI” cycle is even bigger than them all.
There are a lot of reasons for that, which I’m going to get into as part of this … probably very lengthy post about Generative AI in general, where I find it useful, where I don’t, where my personal ethics land on the various elements of GenAI (and I’ll be sure to treat LLMs and Diffusion models differently). So, by the end of this, if I’ve done my job right, you’re going to understand a bit more about why I think there’s a lot of hype and not a lot of substance here — and how we’re going to do a lot of damage in the meantime.
Never you worry friends, I’m going to link to a lot of sources for this one.
If you’ve been living deep in a cave with no access to the news you might not have heard about Generative AI. If you are one of those people and are reading this, I envy you - please take me with you. I’m going to go ahead and define AI for the purposes of this article because the industry has gone and overloaded the term “AI” once again.
I’m going to be very constrained to “Generative AI”, also known as “GenAI”, of two categories: Large Language Models (LLMs) and Diffusion Models (like Dall-E and Stable Diffusion). The way they work is a little bit different, but the way they are used is similar. You give them a “prompt” and they give you some output. For the former, this is text and for the latter this is an image (or video, in the case of Sora). Sometimes we slap them together. Sometimes we slap them together 6 times.
Examples of LLMs: ChatGPT, Claude, Gemini (they might rename it again after this post goes live because Google gonna Google).
I’m going to take my best crack at summarizing how this works, but I’ll link to more in-depth resources at the end of the section. In its most basic terms, an LLM takes the prompt that you entered and then it uses statistical analysis to predict the next “token” in the sequence. So, if you give it the sentence “Cats are excellent”, the LLM might have correlated “hunters” as the next token in the sequence as statistically 60% likely. The word “pets” might be 20%. And so on. It’s essentially “autocomplete with a ton of data fed to it”.
Sidebar, a token is not necessarily a full word. It could be a “.”, it could be a syllable, it could be a suffix, and so on. But for the purposes of the example you can think of as words.
What the LLM does that makes it “magical” and able to generate “novel” text is that sometimes it won’t pick the statistically most likely next token. It’ll pick a different one (based on its Temperature, Top-P, and Bottom-P parameters), which then sends it down a different path (because the token chain is now different). This is what enables it to give you a Haiku about your grandma. It’s also what makes it generate “alternative facts”. Also known as “hallucinations”.
This is a feature.
You see, the LLM has no concept of what a “fact” is. It only “understands” statistical associations between the words that have been fed to it as part of its dataset. So, when it makes up court cases, or claims public figures have died when they’re very much still alive, this is what’s happening. OpenAI, Microsoft, and others are attempting to rein this in with various techniques (which I’ll cover later), but ultimately the “bullshit generation” is a core function of how an LLM works.
This is a problem if you want an LLM to be useful as a search engine, or in any domain that relies on factual information, because invariably it will make fictions up by design. Remember that, because it’s going to come up over and over again.
I don’t understand diffusion models as well as I understand language models, much like I understand the craft of writing more than I do art, so this is going to be a little “fuzzier”
Basically, a Diffusion model is the answer to the question “what happens if you train a neural network on tagged images and then introduce progressively more random noise?” The process works (massively simplified) like this:
The model is given an image labeled “cat”
A bit of random noise (or static) is introduced into the image.
Do Step 2 over and over again until the image is totally unrecognizable as a cat.
Congrats! You now know how to make a “Cat” into random noise.
But the question then becomes “can we reverse the process?”. Turns out, yes, you can. To get a from a prompt of “Give me an image that looks like a cat” the diffusion model will do the process in essentially reverse:
We generate an image that is nothing but random noise.
The model uses its training data to “remove” that random noise, just a bit
Repeat step 2 over and over again
Finally, you have an image that looks something akin to a cat
Now, on this other side, your model might not have generated a great cat. It doesn’t know what a cat is. So, it asks another model: “Hey, is this an acceptable cat?” Said model will either say “nope, try again”, or it will respond with “heck yes! That’s a cat. Do more like that”.
This is Reinforcement Learning - this is going to come up again later.
So, at it’s most “basic” representation the things that are making “AI Art” are essentially random noise de-noiserators. Which, at a technical level is super cool! Who would have thought you could give a model random noise garbage and get a semi-coherent image out of the other end?
I mean, it’s $20/mo for an OpenAI ChatGPT pro subscription, how expensive could it be?
My friends, this whole industry is propped up by a massive amount of speculative VC / Private Equity funding. OpenAI is nowhere near profitable. Their burn rate is enormous (partly due to server costs, but also training foundational models is expensive). Sam Altman is seeking $7 Trillion dollars for AI chips. Moore’s law is Dead, so we can’t count on the cost of compute getting ever smaller.
Let’s also talk about the environmental impact of some of these larger models. Training them requires a lot of water. Using them uses way less water (well, as much as running a power-hungry GPU would require), but the overall lifecycle of a GenAI large foundational model isn’t exactly sustainable in the world of impending climate crises.
One thing that’s also interesting is there are a number of smaller, useable-ish models that can run on commodity hardware. I’m going to talk about those later.
I think part of what’s fueling the hype here is only a few companies on the planet can currently field and develop these large foundational models, and no research institutions currently can. If you can roll out “AI” to every person who uses a computer, your potential and addressable markets are enormous.
Because there are only a few players in the space, they’re essentially doing what Amazon is an expert at: Subsidize the product to levels that are unsustainable (that $20/mo, for example) and then jack up the price later once you’ve got a captive market that has no choice in the matter anymore.
We’re already seeing them capture a lot of market here, too, because a ton of startups are building features which simply ask you, the audience, to provide an OpenAI API key. Or, they subsidize the API access cost to OpenAI through other subscription fees. Ultimately, a very small number of players under the hood control access and cost…. which is going to be very very “fun” for a lot of businesses later.
I do think OpenAI is chasing AGI…for some definition of AGI; but I don’t think it’s likely they’re going to get there with LLMs. I think they think that they’ll get there, but they’re now chasing profit. They’re incentivized to say they’ve got AGI even if they don’t.
I’m getting pretty sick of hearing this one, because the concept of a computer Neural Network is pretty neat but every time someone says “and this is how a human brain works” it drives me a little bit closer to throwing my laptop in a river.
It’s not. Artificial Neural Networks (ANNs) were invented in the late 1960s, and were modeled after a portion of how we thought our brains might work at the time. Since then, we’ve made advances with things like Convolutional Neural Networks (CNNs) starting in the 1980s, and most recently Transformers (this is what ChatGPT uses). None of these ANN models actually model what the human brain is actually doing. We don’t actually understand how the human brain works in the first place, and the entire field of neuroscience is constantly making discoveries.
Did Transformer architecture stumble upon how the human brain works? Unlikely, but, hey, who knows. Let’s throw trillions of dollars at the problem until we get sentient clippy.
Look, I could get into a lengthy discussion about whether free will exists but I’m gonna spare you that one.
Couple of things here: it’s really hard to model how well a generative AI tool is doing on benchmarks. Pay attention to the various studies that have been released (peer reviewing OpenAI’s studies has been hard, turns out). You’re not getting linear growth with more data. You’re not getting exponential growth (which I suspect is what the investors are wanting).
You’re getting small incremental improvements simply from the adding more data. There are some things that the AI companies that are doing to improve performance for certain queries (this is human reinforcement, as well as some “safety” models and mechanisms) - but the idea that you just keep feeding a foundational model more data and it suddenly becomes much better is a logical fallacy and there’s not a lot of evidence for it.
The shortest answer is “a whole bunch of copyrighted content that a non-profit scraped from the internet”. The longer answer is “we don’t actually fully know because OpenAI will not disclose what’s in their datasets”.
One of the datasets, by the way, is Common Crawl - you can block its scraper if you desire. That dataset is available for anyone to download.
If you’re an artist that had a publicly accessible site, art on Deviantart, or really anywhere else one of the bots can scrape, your art has probably been used to train one of these models. Now, they didn’t train the models on “the entire internet”, Common Crawl’s dataset is around 90 TB compressed, and most of that is…. Well, garbage. You don’t want that going into a model. Either way, it’s a lot of data.
If you were a company who wanted to get billions of dollars in investment by hyping up your machine learning model, you might say “this is just how a human learns to do art! They look at art, and they use that as inspiration! Exactly the same.”
I don’t buy that. An algorithm isn’t learning, it’s taking pieces of its training set and reproducing it like a facsimile. It’s not making anything new.
I struggle with this a bit too. One of my favorite art series is Marcel Duchamp’s Readymades - because it makes you question “what is art, really?”. Does putting a urinal on its side make it art? For me, yes, because Duchamp making you question the art is the art. Is “Hey Midjourney give me Batman if he were a rodeo clown” art? Nah.
Thus, OpenAI is willing to go to court to make a fair use argument in order to continue to concentrate the research dollars in their pockets and they’re willing to spend the lobbying dollars to ask forgiveness rather than waiting to ask permission. There’s a decent chance they’ll succeed. They’ll have profited off of all of our labor, but are they contributing back in a meaningful way?
Let’s explore.
Part 2, or “how useful are these things actually”?
Let’s start with LLMs, which the AI companies claim to be a replacement for writing of all sorts or (in the case of Microsoft) the cusp of a brilliant Artificial General Intelligence which will solve climate change (yeahhhhh no).
Remember above how LLMs take statistically likely tokens and start spitting them out in an attempt to “complete” what you’ve put into the prompt? How are the AI companies suggesting we use this best?
Well, the top things I see being pushed boil down to:
Replace your Developers with the AI that can do the grunt work for you
Generate a bunch of text from some data, like a sales report or other thing you need “summarized”
Replace search engines, because they all kind of suck now.
Writing assistants of all kinds (or, if you’re an aspiring grifter, Book generation machine)
Make API calls by giving the LLM the ability to execute code.
Chatbots! Clippy has Risen again!
There are countless others that rely on the Illusion that LLMs can think, but we’re going to stay away from those. We’re talking about what I think is useful here.
The Elephant in the Software Community: Do you need developers?
Okay, there are so many ways I can refute this claim it’s hard to pick the best one. First off, “prompt engineering” has emerged as a prime job, and it’s really just typing various things into the LLM to try and get the best results (again, manipulating the statistics engine into giving you output you want. Non-deterministic output). That is essentially a development job; you’re using natural language to try to get the machine to do what you want. Because it has a propensity to not do that, though, it’s not the same as a programming language where it does exactly what you tell it to, every time. Devs write bugs, to be sure, but what the code says is what you’re going to get out the other end. With a carefully crafted prompt you will probably get what you want out the other end, but not always (this is a feature, remember?)
The folks who are financially motivated to sell you ever increasingly complex engines are incentivized to tell you that you can cut costs and just let the LLM do the “boring stuff” leaving your most high-value workers free to do more important work.
And you know what, because these LLMs were trained on a bunch of structured code, yeah, you probably can get it to semi-reliably produce working code. It’s pretty decent at that, turns out. You can get it to “explain” some code to you and it’ll do an okay (but often subtly wrong) job. You can feed it some code, tell it to make modifications, or write tests, and it’ll do it.
Even if it’s wrong, we’ve built up a lot of tooling over the years to catch mistakes. Paired with a solid IDE, you can find errors in the LLMs code more readily than just reading it yourself. Neat!
I actually tried this recently when revamping the GW2 Assistant app. I’ll be doing a post on my experiment doing this soonish, but in the meantime let me summarize my thoughts (which are actually the second point):
An experienced developer knows when the LLM has produced unsustainable or dangerous code, and if they’re on guard for that and critically examine the output they probably will be more efficient than they were before.
Inexperienced developers will not be able to do that due to unfamiliarity and will likely just let the code go if it “works”. If it doesn’t work, they’re liable to get stuck for far longer than pair programming with a human.
Devin, the AI Agent that claims to be the first AI software engineer looks pretty impressive! Time for all software devs to take up pottery or something. I want you to keep an eye on those demos and what the human is typing into the prompt engine. One thing I noticed in the headline demo is that the engineer had to tell Devin 3 or 4 times (I kinda lost count) that it was using the wrong model and “be sure to use the right model”. There were also several occasions where he had to nudge it using specialized knowledge that the average person is simply not going to have. Really, go check it out.
Okay, so, we’re safe for a little bit right?
Well….no. I’m going to link to an article by Baldur Bjarnason: The one about the web developer job market. It’s pretty depressing, but it also summarizes my feelings well. Regardless of the merits of these AI systems (and I have a sneaking suspicion that the bubble’s going to pop sooner rather than later due to the intensity of the hype), CTOs and CEOs that are focused on cutting costs are going to reduce headcount as a money-saving measure, especially in industries that view software as a Cost Center. Hell, if Jensen Huang says we don’t need to train developers, we can be assured that the career is dead.
I think this is a long-term tactical mistake for a few reasons:
I think a lot of the hype is smoke-and-mirrors, and there’s no guarantee that it’s going to be orders-of-magnitude better.
We’ll make our developer talent pool much smaller, and have little to no environment for Juniors to learn and grow, aside from using AI assistants to do work.
Once the cost of using AI tools increases, we’ll be scrambling to either rehire devs at deflated cost, or we’re going to try and wrangle less power hungry models into doing more development things.
This LLM wish fulfillment strategy is essentially “I don’t have time to crunch this data myself, can I get the AI to do it for me and extract only the most important bits”. The shortest answer is “maybe to some degree of accuracy”. If you feed it a document, for example, and ask it to summarize - odds are decent that it’ll both give you a relatively accurate summary (because you’ve increased the odds that it’ll produce the tokens you want to see in said document) that will also contain degrees of factual errors. Sometimes there will be zero factual errors. Sometimes there will be many. Whether those are important or not depends entirely on the context.
Knowing the difference would require you to read the whole document and decide for yourself. But we’re here to save time and be more productive, remember? You’re not going to do that. You’re going to trust that the LLM has accurately summarized the data in the text you’re giving it.
BTW, by itself an LLM can’t do math. OpenAI is trying to overcome this limitation by allowing it to run Python code or connect to Wolfram Alpha but there are still some interesting quirks.
So, you trust that info, and you take it to a board presentation. You’re showcasing your summarized data and it clearly shows that your Star Wars Action Figure sales have skyrocketed. Problem is you’re an oil and gas company and you do not sell Star Wars action figures. Next thing you know, you’re looking like an idiot in front of the board of directors and they’re asking for your resignation. Or, worse, the Judge is asking you to produce the case law your LLM fabricated, and now you’re being disbarred. Neat!
Remember, the making shit up is a feature, not a bug.
But wait! We can technology our way out of this problem! We’ll have the LLM search its dataset to fact check itself! Dear reader, this is Retrieval Augmented Generation (RAG). Based on nothing but my own observations, the most common technique I’ve seen for this is doing a search first for the prompt, injecting those results into the context window, and then having it cite its sources. That can increase the accuracy by nudging the statistics in the right direction by giving it more text. Problem is, it doesn’t always work. Sometimes it’ll still cite fake resources. You can pile more and more stuff on top (like doing another check to see if the text from the source appears in the summary) in an ever-increasing race to keep the LLM honest but ultimately:
LLMs have no connection to “truth” or “fact” - all the text they generate are functionally equivalent based on statistics
RAG and Semantic Search are related concepts - you might use a semantic search engine (which attempts to search on what the user meant, not necessarily what they asked) to retrieve the documents you inject into the system.
The other technique we really need to talk about briefly is Reinforcement Learning from Human Feedback (RLHF). This is “we have the algorithm produce a thing, have a human rate it, and then use that human feedback to retrain / refine the model”.
Two major problems with this:
It only works on the topics you decide to do it on, namely “stuff that winds up in the news and we pinky swear to ‘fix’ it”.
You’d be surprised just how much of our AI infrastructure is actually Mechanical Turks. Take Amazon Just-walk-out, for example.
What we wind up doing is just making the toolchain ever more complicated trying to get spicy autocomplete to stop making up “facts”, and it might have just not been worth the effort in the first place.
Google’s been fighting a losing battle against “SEO Optimized” garbage sites for well over a decade at this point. Trying to get relevant search results amidst the detritus and paid search results has gotten harder over time. So, some companies have thought “hey! Generative AI can help with this - just ask the bot (see point #6) your question and it’ll give you the information directly”.
Cool, well, this has a couple of direct impacts, even if it works. Remember those hallucinations? They tend to sneak in places where they’re hard to notice, and its corpus of data is really skewed towards English language results. So, still potentially disconnected from reality (but usually augmented via RAG), but how would you know? It’s replaced your search engine - so are you going to now take the extra time to go to the primary source? Nah.
Buuuut, because Generative AI can generate even more of this SEO garbage at a record pace (usually in an effort to get ad revenue) we’re going to see more and more of the garbage web showing up in search. What happens if we’re using RAG on the general internet? Well, it’s an Ouroboros of garbage, or, as some folks theorize, Model Collapse.
The other issue is that if people just take the results the chat bot gives them and do not visit those primary sources, ad revenue and traffic to the primary sources will go down. This disincentivizes those sources from writing more content. The Generative AI needs content to live. Maybe it’ll starve itself. I dunno.
But it’ll help me elevate my writing and be a really good author right?
I’ve been too cynical this whole time. I’m going to give this one a “maybe”. If you’re using it to augment your own writing, having it rephrase certain passages, or call out to you where there are grammar mistakes, or any of that “kind” of idea more power to you.
I don’t do any of that for two reasons, one is practical, the other highlights where I think there’s an ethical line:
I’m not comfortable having a computer wholesale rewrite what I’ve done. I’d rather be shown places that can improve, see some other examples, and then rewrite it myself.
There’s a pretty good chance that the content it regurgitates is copyrighted, and we’re still years out from knowing the legal precedent.
The AI industry has come up with a nice word for “model regurgitates the training data verbatim”. Where we might call it “plagiarism” they call it “overfitting”.
Look, I don’t want to be a moral purist here, but my preferred workflow is to write the thing, do an editing pass myself, and then toss the whole thing into a grammar checker because my stupid brain freaking loves commas. Like, really, really, loves them. Comma.
I do this with a particular tool: Pro Writing Aid. It’s got a bunch of nice reports which will do things like “highlight every phrase I’ve repeated in this piece” so that I can see them and then decide what to do with them. Same deal with the grammar. I ignore its suggestions frequently because if I don’t, the piece will lose my “voice” - and you’ll be able to tell.
They, like everyone else, have started injecting Gen AI stuff into their product, but for me it’s been absolutely useless. The rephrase feature hits the same bad points I mentioned earlier. They’ve also got a “critique” function which always issues the same tired platitudes (gotta try it to understand it, folks).
This raises another interesting point about the people investing in Generative AI heavily. One of those companies is Microsoft. A company who makes a word processor. The parent of clippy themselves. They could have integrated better grammar tools into their product. They could have invested more in “please show me all the places where I repeated the word ‘bagel’”. They didn’t do this.
That makes me think that they didn’t see the business case in “writing assistants”, and why Clippy died a slow death.
Suddenly, though, they have a thing that can approximate human writing and suddenly there’s a case and a demand for “let this thing help you write”. I feel like they’re grasping at use cases here. We stumbled upon this thing, it’s definitely the “future”, but we don’t…quite….know….how.
I want to take a second here to talk about a lot of what I’m seeing in the business world’s potential use cases. “Use this to summarize meetings!” or “Use this to write a long email from short content” or “Here, help make a presentation”.
Essentially what you’re seeing is a “hey, busywork sucks, let’s automate the busywork”. Instead of doing that, why not just…not do the busywork? If you can’t be bothered to write the thing, does it actually have any value?
I’m not talking about documentation, which is often very important (and should be curated rather than generated), but all those little things that you didn’t really need to say.
If you’re going to type a bulleted list into an LLM to generate an email, and the person on the other end is going to just use an LLM to summarize, lossily, I might add, why didn’t you just send the bulleted list?
You’re making more work for yourself. Just… don’t do that?
Right, so one of the fun things OpenAI has done for some of their GPT-4 products is to give it the ability to make function calls, so that you can have it do things like:
Book a flight
Ask what the next Guild Wars 2 World Boss is
Call your coffee maker and make it start
Get the latest news
Tie your shoes (not really)
And so on. Anything you can make a function call out to, you can have the LLM do!
It does this by being fed a function signature, so it “knows” how to structure the function call, and then runs it through an interpreter to actually make the call (cause that seems safe).
Here’s the…minor problem. It can still hallucinate when it makes that API call. So, say you have a function that looks like this: buyMeAFlight(destination, maxBudget) and you say to the chatbot “Hey, buy me a flight to Rio under $200”. What the LLM might do is this: buyMeAFlight("Rio de Janeiro", 20000). Congrats, unless you have it confirm what you’re doing you just bought a flight that’s well over your budget.
Now, like all other Generative AI things, there are techniques you can use to increase the accuracy. Making just the perfect prompt, having it repeat output back to you, asking “are you sure”, telling it that it’s a character on star trek. You know, normal stuff.
Alternatively you could just... use something deterministic, like, I don’t know, a web form or any of the existing chat agent software we already had.
Sidebar: Apparently OpenAI has introduced a “deterministic” mode in beta, where you provide a seed to the conversation to get it to reliably reproduce the same text every time. Are you convinced this is a random number generator yet?
So the “killer” application we’ve come up with, over and over, is “let’s type our question in natural language and it does a thing.” I honestly don’t understand this on a personal level - because I don’t really like talking to chatbots. I don’t want to say “Please book me a flight on Friday to New York” and then forget about it. I want to have control over when I’m going to fly.
Do large swaths of people want executive assistants to do important things like cross-country travel?
Not coincidentally, I really struggle with that kind of delegation and have never really made use of an executive assistant personally.
We’ve decided that the best interface for doing work is “ask the chatbot to do things for you” in the agent format. This is exactly the premise of the Rabbit R1 and the Humane Ai Pin. Why use your phone when you can shout into a thing strapped to you and it’ll do…whatever you ask. Perhaps it’ll shout trivia answers at you.
But guess what, my phone can already do that. Siri’s existed for years and like, I hardly use it. It’s not because it’s not useful. It’s because I can do what I want without shouting at it. In public. For some reason.
We do need to talk about accessibility. One of the things that AI agents would be legitimately useful for is for those folks who cannot access interfaces normally whether that’s situationally (driving a car), or temporarily / permanently (blind, disabled).
If we can use LLMs to get better accessibility tech that is reliable, I’m all for it. Problem is that the companies pushing the technology have a mixed track record on doing accessibility work, and I’m concerned that we’ve decided that LLMs being able to generate text means we can abdicate responsibility for doing actual accessibility work.
Like many other things in the space, we’ve decided that “AI” is magic, and will make things accessible without having to do the work. I mean, no. That’s not how it works.
Remember back to the beginning of this article where I talked about other Machine Learning Models? I think that’s the space where we’re going to make more accessibility advances, like the Atom Limb which uses a non-generative model to interpret individual muscle signals.
If I had to summarize my thoughts on all of the above it’s that we’ve stumbled upon something really cool - we’ve got an algorithm that can create convincing looking text.
The companies that have the resources to push this tech seem to be scrambling for the killer use-case. Many companies are clamoring for things that let them reduce labor costs. Those two things are going to result in bad outcomes for everyone.
I don’t think there’s a silver bullet use case here. There are better tools already for every use case I’ve seen put forward (with some minor exceptions), but we’re shoving LLMs into everything because that’s where the money is. We’re chasing a super-intelligent god that can “solve the climate crisis for us” by making the climate crisis worse in the meantime.
If you were holding NVDA stock, something something TO THE MOON. They’ve been making bank off of every bubble that needs GPUs to function.
This feels exactly like the Blockchain and Web3 bubbles. Lots of hype, not a lot of substance. We’re tying ourselves in knots to get it to not “hallucinate”, but like I’ve repeated over and over again in this piece the bullshit is a feature, not a bug. I recommend reading this piece by Cory Doctorow: What Kind of Bubble is AI? It’ll give you warm fuzzies. But it won’t.
Midjourney, Sora, all those things that can fake voices and make music. We’ve got a big category of things that are, charitably “art generators”, but more realistically “plagiarism engines”.
This section is going to be a lot shorter. Let me summarize my feelings:
If you’re using one of these things for personal reasons, making character art for your home D&D game, or other things that you’re not trying to profit from - go for it. I don’t care. I’d rather you not give these companies money but I don’t have moral authority here.
I’ve used it for this too! I’m not exempt from this statement.
If you’re using AI “art” in a commercial product, you don’t have an ethical defense here (but we’ll talk about business risk in a sec). The majority of these models were trained on copyrighted content without consent and the humans who put the work in are not compensated for it.
I personally don’t find all of the existing AI creations that inspiring, other than how neat it is we’ve gotten a neural network to approximate images in its training set. Some of the things it spits out are “cool” and “workable” but I just don’t like it.
Hey, I do empathize with the diffusion models a bit though. Hands are hard.
As I mentioned earlier in the post, as far as we can tell, the art diffusion models were trained on publicly viewable, but still copyrighted content.
If for some reason you’re a business and you’re reading this post: That’s a lot of business risk you’d be shouldering. There are multiple different lawsuits happening right now, many of them on different lines, and we don’t actually know how that’s going to go. Relatedly, AI Art is not copyrightable, so that’s…probably a problem for your business especially if you’re making a book or other art-heavy product. At best you can do is treat it like stock art, where you don’t own the exclusive rights to the art, and you’re hoping you don’t get slapped with liability in the future.
So, if you’re using an AI Art model in your commercial work, these are all things you have to worry about.
This is where, and I cannot believe I am saying this, I think Adobe is playing it smart. They’ve trained Firefly on Art they’ve licensed from their Adobe Stock art platform and are (marginally) compensating artists for the privilege. They have also gone so far as to offer to guarantee legal assistance to enterprise customers. If you’re a risk averse business, that’s a pretty sweet deal (and less ethically concerning - though the artists are getting pennies).
The rest of them? You’re carrying that risk on your business.
AI companies seem hell bent on both automating the act of creation (devaluing artistry and creativity in the process) and also making it startlingly easy for fraudsters to do their thing.
So, you create things that can A) Clone a person’s voice, B) Imitate their Likeness, and C) Make them say whatever you want.
WHAT THE HELL DID YOU THINK WAS GOING TO HAPPEN? WHAT PUBLIC GOOD DOES THAT SERVE?
I dunno about y’all, but I’m okay not practicing Digital Necromancy (just regular, artisanal necromancy).
The commercial business for these categories of generative AI are flat out fraud engines. OF COURSE criminals are going to use this to defraud people and influence elections. You’ve made their lives so much easier.
Hey, I guess we can take solace in the fact that the fraud mills can do this with fewer employees now. Neat.
But Netflix Canceled My Favorite Show and I want to Revive it
This is also known as the “democratizing art” argument. First thing I would like to point out is that art is already democratized? It’s a skill. That you can learn. All you need to do is put in the time. It’s not a mystical talent that only a select few possess.
Artists are not gurus who live in the woods and produce art from nothing, and the rest of us are mere drones who are incapable of making art.
So in this case “democratization” really means “can make things without putting in the effort”. The result of that winds up being about as tepid as you might imagine.
Now, there’s a question in there of if a person is having to work all the time to simply live, won’t this enable them to “make art”? There’s another way to fix that, by reducing the amount of work they need to do to simply exist, but nah, we’re gonna automate the fun parts.
Hey, awesome artists who are making things with AI tools but are using it as a process augmenter - all good. I’m not talking to you. I’m talking to the Willy Wonka Fraud Experience “entrepreneurs”
But you know what, I’m not even really that concerned with people who want to make stuff on their own that is for their own enjoyment. I don’t think the result is going to be very good, and I’d rather have more people creating good stuff than fewer, but hey more power to ya.
Another aside: I really do not want to verbally talk to NPCs in games. I play single-player games to not talk to people. I don’t want to be subjected to that in the name of “more realistic background dialog”.
It’s just not going to work out like you think it will. What’ll actually happen is:
The primary thing I suspect is going to happen with the AI “art” is back to the cost-cutting efforts. Where you might have used stock art before, or a junior artist, you’re going to replace that with Dall-E.
For marketing efforts, that’s not an immediate impact. Marketing content is designed to be churned out quickly, and shotgunned into people’s feeds in an effort to get you to buy something or to feel some way, etc. I don’t think those campaigns are going to be as effective as the best campaigns ever, but eh, we’ll see I guess.
The most concerning uses are going to be the media companies that are going to replace assets in video games and movies. Fewer employees, lower budgets, and … dare I say … lower quality.
You see, diffusion models don’t let you tweak them, yet (although, who knows, maybe if we start doing deterministic “seeds” again we’ll get somewhere with how Sora functions). They also have a propensity to not give you what you asked for, so, yeah, let’s spend billions of dollars trying to fix that.
So, at risk of trying to predict the future (which I’m definitely bad at), I think we’re going to gut a swath of creatives, devalue their work, and then realize that “oh, no one wants this generative crap”. We’ll rehire the artists at lower rates and we’ll consolidate capital into the hands of a few people.
Meanwhile, we’ve eliminated the positions where people would traditionally learn skills, so you won’t be able to have a career.
We live in a society that requires money to function. Most of us sell our labor for the money we need to live.
The goal of companies is to replace as many of their workers as they can with these flawed AI tools. Especially in the environment we find ourselves in where VC money needs to make a return on investment now that the Zero Interest Rate Phenomenon (ZIRP) is finished.
Now, “every time technology has displaced jobs we’ve made more jobs” is the common adage. And, generally, that’s true. However, the main fear here isn’t that we won’t be working, it’s that it’ll have a deflationary impact on wages and increase income inequality. CEO compensation compared to average salary has increased by 1460% since the 70’s, after all.
What I think is different about previous technological advances (but hey, the Luddites were facing similar social problems) is that we’re in a situation where the amount of capital is being invested in the hands of a few companies, and only a very few of them have the resources to control this new technology. I don’t think they’re altruists.
This is not a post-scarcity Star Trek future we’re living in. I wish we were. I’m sorry.
Right. Uh. I’m not sure I can, but here are some things I’d like to see:
There are a number of really small models that can run on commodity hardware, and with enough tuning you can get them to give you comparable results to what you’re getting on some of the larger models. Those don’t require an ocean of water to train or use, and run locally.
Check out Faraday or Jan.ai if you want to play around.
We’re going to see more AI chips, that’s inevitable, but the non-generative models are going to benefit from that too. There’s a lot of interesting work happening out there.
I’m also pretty cool with DLSS and RSR for upscaling video game graphics for lower-powered hardware. That’s great.
I honestly hope I’m wrong and that the fantastical claims about AI solving climate change are real… but the odds of that are really bad.
This is the longest post I think I’ve ever written, we’re well over 7,000 words. I have so many thoughts it’s hard to make them coherent.
Perhaps unsurprisingly, I’ve not used Generative AI (or AI of any kind) for this post. I’ve barely even edited it. You’re getting the entire stream of consciousness word vomit from me.
Call me a doomer if you want, but hey, if you do, I’ve got a Blockchain to sell you.
Update 7-13-24: The tl;dr of this post is "You shouldn't use these, it's not worth it", in case that's unclear.
What happens when you get an extreme “GenAI Skeptic” and shove him in front of an LLM coding assistant? This, turns out.
This is a follow up on my last post, which was an epic rant about Generative AI. In that, I mentioned that while I’m generally skeptical about GenAI replacing developers (for a few different reasons, but also because they can’t do what their promoters say they can), I do think it’s one of the use cases where it could actually be useful as a productivity augment for the “write code” portion of the project (if it worked better and wasn't setting the planet on fire to do it).
I don’t think it’s going to actually be able to replace developers. I think that the AI companies want you to think it’s going to be able to replace developers, but they’re not currently capable of doing so. Watch this video on Debunking Devin by Internet of Bugs, it’s a good watch.
Likewise, the “writing code” portion of software development isn’t the main point of software development, and the LLM can’t do all the fiddly human bits of creating a software product.
Before I get into how I’ve tested this myself I want to call out a couple of posts from people I respect that cover GenAI more thoughtfully and less “cathartic rant-centric” than I was.
First up, Molly White wrote AI isn’t useless. But is it worth it?. Go read it, it’s great. In it, she mentions something I’m glad she did: there are other, better, tools that use way less energy than existing tools for proofreading / editing / grammar checking. But I basically agree with the entire post (and I think it makes a lot of the same points I did, more elegantly and thoughtfully).
The other one is a Guardian Article (which….wow I’m linking to the Guardian), that talks about the AI bubble we’re definitely in.
The tl;dr or “I’m going to have GPT summarize this for me"
I want to emphasize that these are my opinions, and if you find LLMs for coding personally useful, that’s okay. I don't think you should use them, though, and I'm getting to the point where if you mention "I used GPT for..." it's more likely that I'm going to not give the rest of your argument much weight. I also want to call out that I do not use Generative AI for my writing. There are other tools for editing and grammar checking and thesauruses and so on.
For me, there’s some utility in how these things operate. That utility is variable and hard for me to properly quantify. Sometimes, it’s a time save. Sometimes, it’s a time sink. If I had to guess, I’d say it’s a net time-save right now, but that time save is not nearly enough to offset the environmental and social costs.
“But Alex, these will get exponentially better, and will eventually do everything for you”, you might be saying. I’m not trying to set up a straw man. This is what the AI companies are selling. I don’t actually think this is true. My prediction is that we’re already reaching the end of the exponential growth curve, and the amount of utility we can get out of LLMs will plateau.
And look, even if I’m wrong, the change of pace here is so fast - you’re not going to be missing out if you don’t adopt LLMs for coding right now. If you’re a business owner, I’d argue that waiting a bit longer makes more business sense because I suspect once the free money runs out and these folks need to turn a profit the cost is going to go way up, and you’re going to have to recalculate your costs again.
So maybe it’ll be more useful (for me) eventually. Maybe they’ll solve the energy requirements and you can run one of these models locally.
I’m just one guy talking about his own experiences with a Coding LLM. I obviously think I’m right, otherwise I would be singing a different tune, but I want to drop a quote here:
IOW, everything written about LLMs from the perspective of a single practitioner can be dismissed out of hand. The nature of LLMs makes it impossible to distinguish signal from noise in your own practice. - Baldur Bjarnason, The Intelligence Illusion
That is to say, any individual account, whether positive or negative for LLMs, is inherently biased. (See also - You should not be using LLMs)
If you want a counterpoint, go have a look at Simon Willison’s blog, which Molly linked to in her article. I disagree with his assessment of the ethics and the inevitability, but go have a look and learn for yourself.
Sidebar: Even his posts that have nothing to do with Generative AI have started to include statements like "So I asked GPT-4o to help me...".
Okay, that out of the way, let’s talk about the Coding Experiment.
I set a couple of rules for myself to try and make this experiment have some constraints so that I can emulate how I’d expect a competent coding assistant to function.
Minimal “prompt engineering”. The tool can inject whatever context it wants, but I’m going to use the tool as the marketing says I should be able to.
Likewise, if I need to type out more words to describe what I want than it’d have taken to simply write the code…. that’s not great.
Working on a well-represented language: Typescript is well-represented in GPT’s dataset.
Real project I’m working on.
No googling, only doing what the Assistants tell me to do.
Here are the tasks I’m going to accomplish:
Replace the Deprecated ‘request’ module with Axios in the http class.
Fix the failing unit tests and refactor them to use async / await
Fix a problem with getDeeperInfo related to closures / scope.
I’ve chosen 3 different projects to run this test on:
Zed with GPT-4-turbo
Continue.dev (Extension) on VS Code with GPT-4-Turbo
Github Copilot on VS Code
The first two are because I want to do a “control” for the LLM (though they do use slightly different versions). The last one is just for a commercial-off-the-shelf “optimal” experience.
I don’t know what extra context the tools are injecting before sending data to their LLM counterpart, but hopefully by doing two with the same model we’ll get a decent comparison between the two.
I’m not really looking to rate any of these things as a clear “winner”, but I did want to see if any of these clearly outperformed each other.
Copilot had the weirdest behavior of them all, it would frequently not update the code inline even when I told it to. It also was the only one that flat out started removing braces, leading to a fun little compile error.
But, overall eventually each of the three were able to assist with the tasks. They all performed “best” at transforming existing code - all three of them were able to turn promises into async/await without too much trouble.
All three of them had some issues with creating more code than was necessary, or generating code that doesn’t work. They all did a decent job of summarizing code (with some fun little inaccuracies), and usually were able to help me spot things like a missing return statement that an IDE could notice, but is frequently not configured to notice.
Like I said in the tl;dr - these things were fiddly and inconsistent. Frequently, the built-in IDE features we’ve already had were much better. What you're being sold right now is a future where this works better, which would be "fine" if the hype cycle weren't also selling these tools as a "Developer replacer" to execs (shout out to Copilot for slapping warnings of "this doesn't replace human effort" all over the actual tool... but it's not going to be enough).
So the first test actually took the longest, largely because this was the test where I had no prior experience with the issues that I need to fix. The second and third tests got progressively faster as I knew where to look for things, but the LLM got a little… “spicy”.
If you want to have a look at the test, here’s the video:
First off, it did a fine job replacing requests with axios, though it (and my undercaffeinated brain) had some issues with the typings. When it came to actually call the API though, it introduced some mistakes with how the API was called. It’s arguable here that I’d have gotten a better result with a better prompt, but looking back to the rules, I shouldn’t have to type a paragraph.
On the second test, it did fine, though I did forget to have it do an async/await in the video. I did try it later, and it worked fine - basically the same as the others. This was probably the most consistent, but it’s also one of the things where I can complete the task / update in about 30-45 seconds and the LLM does it in around 20 seconds (inclusive of typing the prompt).
Sidebar: my best time using liberal copy/paste in that was around 16 seconds. This is what I’m taking about with variable time save.
For the Third test - I wound up not needing the LLM to help with it. It was a missing param on a couple of calls. So, it wound up being unnecessary.
Overall: This was “fine” - and it mostly stayed out of my way while I was doing the experiment, which I appreciate.
Right, so this one was the first of the two that use VS Code Plugins. Continue.dev is an open-source way to call all sorts of LLMs, including locally hosted LLMs. I’ve also given that a shot but the experience untethered from a GPU is not great.
For this test I thought I’d disabled the code autosuggestion, but for some reason the config didn’t stick and it was using…some…. llm’s free trial API for it? I honestly have no idea what happened there and it’s present in the video.
Speaking of video, the commentated test is here:
Like the others, this one did a pretty okay job at each of the tasks, but it had some standouts:
The inline updates worked consistently and made an actually diff in the IDE, so I could accept or reject things individually. That made it a lot easier than Zed to see if the LLM had inserted something that I didn’t want (which happened a lot).
Subjectively I think there were more hallucinations, but it’s the same LLM so that’s probably random.
It’s worth calling out here that all of these calls to the LLM are non-deterministic. If you were to set the temperature to 0 you could get more deterministic behavior but that would also destroy its “creativity” so no one really does that.
Like before, it completed task 1 in a very similar way to Zed, but I had to futz with the output more. It created a similar error when refactoring the actual callAPI method as well - which took a little bit longer to fix.
For task 2, it did just fine, and it was likewise able to eventually figure out there was a missing return statement.
Right, so Copilot was frustrating in more way than one.
Sidebar: Microsoft, I need you to get your shit together and stop naming different products the same thing please.
First off, the inline editing was extremely inconsistent. If you check out the video, you’ll encounter this immediately:
For the first several attempts, it just doesn’t work. It won’t make changes, or even accurately suggest what to do - it just craters and suggests I use the chat sidebar. Eventually it starts working and I assume that it’s looking for cues in the response from the LLM to do its inline replacements but it messes up more than once.
The chat is “fine”, in that it’s a bit verbose (how much money are we burning on extra tokens?) and it’s moderately helpful at times.
For problem 1, I wound up having to use the autosuggest to make the changes, after several failed attempts at the inline changes.
For problem 2, it worked fine - like the others it was able to both suggest the missing return (though it also added a bunch of unnecessary code) and to refactor the tests to be async.
So, for Github Copilot, I’d never used it before so I got to get a 30 day free trial! Hooray!
For Zed and Continue, I was using my OpenAI API key (which yes, I do have an OpenAI API key - I’ve spent about $10 on it total so far for experimentation). Have a look:
I spent $1.55 for approximately 1.5 hours of “light” usage (maybe we be generous and call it 2). If we assume that I’m using that level of usage across all “tasks” that the AI folks envision (like, I’m using Copilot for code and the other Copilot for Emails, because they’re shoving them into absolutely everything) - we can “extrapolate” 160 hours at roughly $0.75 per hour puts us at $120 of usage per month. Were I using GPT-3.5 you can pretty well divide that by 20 (ish) for a usage of $6/mo.
You might notice there’s a math problem here. Assuming Copilot is using GPT-4, and they charge $10/mo - they’re likely loss-leading a lot here. If they’re using a more efficient model….they’re probably still losing money on every subscription unless devs aren’t using features.
I suspect this is also the case for the Office 365 + Edge Browser + everything else - burning investment dollars to get everyone hooked.
I only mention this because I think they’re going to raise prices eventually, unless there’s some egregious advance in chip technology (which Nvidia is chasing), and when they do….
So yeah, to summarize what I said at the beginning, I’m just not getting enough value for these things to justify their use and the ethics and energy use bother me.
If we can get to a point where we’re not burning egregious amounts of energy and these models aren’t consolidating even more capital in the big tech companies, that might change. Maybe we'll get really advanced AI chips that let you run all of these locally on commodity hardware. I just think the current trend of "more power and bigger" is unsustainable.
I still also have some existential concerns with newer developers learning through the use of LLMs, when they'd be better served by really good curated documentation, but I'll leave that for another post.
The International Symposium on Making Web Sites Real good is now over and I watched it live. All of the talks are watchable up on Youtube.
Overall I really enjoyed all of the talks, especially the ones that made me think a lot more about what the internet is about. The whole conference is well worth watching, but I'm just going to call out a few big highlights that I especially enjoyed.
This was an amazing talk all around, and discusses how the web was originally designed to protect content over other concerns and how styling came to exist in a way that respects that end goal. The overall discussion around the history of the web and how browsers preserve and protect the content and then how that interacts with authorial intent on a webpage is just fascinating. There are a bunch of links to old web RFCs as well.
DIGITAL FRONTIERS, INDIEWEB COWBOYS, AND A PLACE ONLINE TO CALL YOUR OWN
Henry was an extremely enthusiastic and energetic presenter and clearly loves the stuff he's talking about. He goes into a speedrun of IndieWeb concepts (which is great because he also does Elden Ring challenge runs), and I really recommend jotting down some of the things he talks about in here. Here are some links to some of the concepts / tech he talks about in the talk.
I especially loved how all of these concepts work together and don't require a major commercial entity to work. You can roll everything yourself. I especially like IndieAuth (even though I do prefer other authentication techniques).
This talk was really fun to watch. Dan talks at length about creating a meta-web interactive story which spans 40 websites, at least one Instagram page, and a bunch of different plot lines of a fictional city. It gives Welcome to Nightvale vibes, and is really reminiscent of some of the best parts of the early web.
That's a lot of domains to keep registered!
It's also thought provoking for me because they did make use of Generative AI (apparently more than they thought they would have) in order to make the site happen. Dan didn't go into detail in the talk about just how they did that, but it would appear that it was largely in the image generation space with some of the "general site copy" being LLM generated.
On one hand, I appreciate that making a project of this size would have been impossible for a team of 2 writers to do previously if you don't want to resort to stock art or other licensed images. Being able to generate fictional people enhanced the story they wanted to tell. They managed to create art, where the focus of the art is the story and not the imagery. The imagery does help sell the fiction of the story, especially when it's a little "weird".
On the other hand, I kinda still think this is a borderline unethical use of the technology since I think it's using a model trained on copyrighted data. This is mitigated somewhat from this not being a directly commercial endeavor, but it still kinda makes me feel weird, ya know?
Note, I'm making an assumption here, I can't find what models they used to do this but I think it's Midjourney rather than something like Firefly.
I'd love to see a discussion of the ethical considerations of undertaking a project like Question Mark, Ohio using generative AI.
Chris talks about a concept called "HTML Web Components" which is essentially "use regular HTML until it hits its limits and then enhance those with web components.
If you know anything about me, you know that I love web components. Love them. I love the concepts behind this talk, and it really gives the vibes of "we used to do this with jQuery but we have better tools now" vibes. Definitely worth a watch.
Chris is an excellent presenter and sticks to VanillaJS rather than using something like Stencil, which is great for learning the actual component API. Also the cadence and tenor of his talk is quite soothing.
This is just fascinating - he dives into the history of Chinese Type Systems and ties them to the web beautifully. I study Japanese (which uses a lot of Chinese characters) and so it was fun to understand how these fonts get rendered, how you optimize for them, and a bunch of other neat things I'd never have thought of.
That's it! I enjoyed the whole conference and really appreciate the community / 11ty / CloudCannon for putting it together. Thanks to all the presenters for their time, and thanks to the chat for awesome commentary.
…and you should disable it. Or not buy a Copilot+ PC.
I’m going to cite every source I’ve got on this, the story out of Microsoft is changing and being “clarified” as this goes on, so I’ll do my best to keep this updated and as accurate as possible.
Update - June 13th, 2024: It just keeps getting better and better. Ars Technica says Microsoft is in full damage control mode with just 2 days to go until rollout.
Update - June 7th, 2024: The Verge is now reporting that Microsoft is going to make some changes after the uproar. I'm not sure this matters, I don't think Microsoft has anyone's trust that they won't make changes in the future to get at all that juicy user-generated data. But good on them for doing something.
Update - June 2nd, 2024: Oh good, Nvidia is partnering to enable this on even more computers. It's going to be basically everywhere soon whether you want it or not. Nice. Apropos of nothing I've moved my Framework to running Bazzite. It's working great so far. Haven't tried an eGPU yet.
Okay, here it is again. Another post about Generative AI. Or, rather, "bad ideas brought about by the generative AI hype cycle". Really, I would rather not be spending more time writing about all of this, but it just keeps finding me somehow. I’m so tired.
Anyway, let's talk about Copilot+ Recall (apparently it’s just “Recall” but that’s really difficult to web search, so I’m going to use Copilot+ in front of it). The idea behind it is that everything you do on your computer, will be screenshotted every {n} seconds and stored by the Neural Processing Unit (NPU) somewhere on your computer. It'll do Optical Character Recognition (OCR) on these screenshots and do some other magical "AI goodness" to enable you to later query for anything you did within the past {n} months (configurable, based on how much storage you want to use). Here's the official Microsoft documentation on the feature.
Sidebar, apparently this is enableable on non-Copilot+ computers, but you have to go out of your way to do it.
You know what else records and stores everything you do on your computer? A rootkit. That's right, this thing that Microsoft is installing and apparently enabling by default on new Copilot+ machines, is behaving exactly like a computer virus wants to.
During setup of your new Copilot+ PC, and for each new user, you're informed about Recall and given the option to manage your Recall and snapshots preferences. If selected, Recall settings will open where you can stop saving snapshots, add filters, or further customize your experience before continuing to use Windows 11. If you continue with the default selections, saving snapshots will be turned on (emphasis mine). — Microsoft
How helpful!
Microsoft's main "defense" has thus far been "but it only stays on your computer and never leaves the network". This totally ignores the fact that viruses that want to gain access to that process could just do that itself, regardless of Microsoft's wishes.
This thing will be an incandescent target for hackers. You'd think that Microsoft would know this, but it seems like in their rush to "win" the AI hype race they've cut some corners (which is unsurprising given their recent track record on security).
Recall's security is entirely based on “but it stays local”
But “stays local” is not the same as “secure”. The only fool-proof security is to not store the thing in the first place, but here we are.
Let’s look at some of the corners they’ve cut.
First off, according to Kevin Beaumont, the NPU takes the text it extracts from the images and stores it in a user-readable sqlite database. This is very convenient for searching! This is also very convenient for any malicious process that happens to be running as you to ship off.
Guess what else it does (or rather doesn't do): obfuscate passwords or other sensitive information:
"Note that Recall does not perform content moderation. It will not hide information such as passwords or financial account numbers. That data may be in snapshots that are stored on your device, especially when sites do not follow standard internet protocols like cloaking password entry." — Techradar
Riiiight, so I'm guessing it's not going to obfuscate things like, I dunno, your bank's website? Possibly showing your full account details?
Are there… any other things you do on your computer that you'd rather not be stored for however long Recall wants to store the screenshots? Nothing? Anyhow, maybe you can take some small solace in the fact that apparently Microsoft does know how to process content and won't store DRM'd things:
"Recall also does not take snapshots of certain kinds of content, including InPrivate web browsing sessions in Microsoft Edge. It treats material protected with digital rights management (DRM) similarly; like other Windows apps such as the Snipping Tool, Recall will not store DRM content." — From that same Techradar article
… Cool. Now, Microsoft claims the following about other browsers:
Recall won’t save any content from your private browsing activity when you’re using Microsoft Edge, Firefox, Opera, Google Chrome, or other Chromium-based browsers.
Which was not the case when they first announced the idea, near as I can tell. So I guess they walked back from the “this only works in Edge”.
The security protecting your Recall content is the same for any content you have on your device. Microsoft provides many built-in security features from the chip to the cloud to protect Recall content alongside other files and apps on your Windows device. Secured-core PC: all Copilot+ PCs will be Secured-core PCs. This feature is the highest security standard for Windows 11 devices to be included on consumer PCs. For more information, see Secured-core PCs. Microsoft Pluton security processor will be included by default on Copilot+ PCs. For more information, see Microsoft Pluton. — Microsoft
Microsoft, buddy. None of those things matter if you trick the user into running something in user space because you’ve granted the user access to that database.
None of those things matter if someone with access to the computer wants to go looking back through your history forever.
By the way, if you go look at the Pluon processor, it doesn’t mention a word about Windows Home edition, so I dunno if every Copilot+ machine is going to come with a Windows Pro license or what?
But surely these things are encrypted on the device using BitLocker? Right?
And on that previous note, only if you have a Business or Pro license?
This one is a little tricky because Microsoft is apparently being a little vague, but by all accounts it looks like Home users get to have unencrypted screenshots just sitting on their laptop. Fun!
Sidebar: To see those screenshots, the user needs to be able to decrypt them so…. Again… virus. Running as the user. Can see them.
Maybe all Copilot+ machines come with Windows Pro? I just dunno.
Many other people who are better able to speak to this problem have pointed out that this is rife for abuse by abusive partners.
In fact, Recall seems to only work best in a one-device-per-person world. Though Microsoft explained that its Copilot+ PCs will only record Recall snapshots to specific device accounts, plenty of people share devices and accounts. For the domestic abuse survivor who is forced to share an account with their abuser, for the victim of theft who—like many people—used a weak device passcode that can easily be cracked, and for the teenager who questions their identity on the family computer, Recall could be more of a burden than a benefit. — Malwarebytes
Some of them definitely will. Look, your corporate computer is already watching what you do for good reason. A corporation needs to know if their systems are being used for nefarious, illegal, or other things that will be a problem for them (exfiltrating product secrets, for example).
This goes to a whole other level. On one hand, this is the ultimate forensic “we need to figure out what happened” tool. On the other hand, it makes the risk of leaving a laptop in the airport more risky than it already is. It increases the damage a successful malware deployment can do.
It also increases the amount of stuff that you potentially have to store for legal holds. Many industries have an obligation to hold on to certain things for extended periods of time. Recall is liable to include information that would fall under those regulatory holds so, congrats, now IT also has to implement an archival process for all of those across their entire fleet.
I guess that’s a long-winded way to say “depends on the company, but please for the love of all that is holy do not do personal stuff on your work’s laptop”.
I, personally, have no idea why anyone would trust Microsoft enough to keep this feature secure, and I’m pretty sure we’re going to see a stark uptick in attacks targeting this feature as it rolls out.
Likewise, it would not surprise me if at some point in the future an update to “send select metadata to Microsoft” pops up because the AI race is fueled by data and the allure of all that distributed data is strong.
I can see how this could be useful. I’ve frequently wanted to find something amorphous that I wasn’t able to readily find…. But the downsides far outweigh that benefit for me. I suggest you strongly weigh the risks vs. the benefits and don’t use this thing.
Update June 17th, 2024 - Ed Zitron has a pretty great take on this where in he argues that the ChatGPT integration is a mere footnote and it doesn't seem like Apple thinks it's going to be useful.
Well here we are again. Yet another giant company has decided to put Generative AI front and center, embedding it inside the operating system. I'm starting to think this is the most cursed timeline possible (not really, but the simulation is getting real weird).
I'm going to get to that, but first I want to take a minute and talk about that WWDC keynote, because it had some other things that I liked and a bunch more "AI/Machine Learning" than they actually mentioned.
Look, right out of the gate, Apple announced a ton of things for each one of their operating systems. They did the thing that Apple always does: Refine some feature something else has had for years and announce it like it was both their idea and revolutionary. They also did something I thought was smart: When a feature is powered by machine learning, they didn't mention that and just talked about what the feature could do. Brilliant! There's a lot of relevant, applicable things that ML can do for you that doesn't sway into the generative category.
These very handy features include:
Categorizing your emails into tabs, a feature Gmail has had since 2013. This is almost certainly using some kind of classifier model to do the work. It'll also likely be a bit of a hot mess (but that's okay).
Showing you relevant bits of trivia about the movie or show you're watching, a feature Amazon has had since 2018ish (Prime Video X-Ray)?
Taking 2d Images and making them into "spatial photos" (giving them depth) using an ML algorithm (I dunno if there's anything comparable to this one)
Shake your head while wearing headphones to decline a call from your Gam Gam (using an ML algorithm to classify a nod vs a shake), a feature some other buds did in 2021.
Tapping your fingers to do actions on your watch, which again is using a classifier model to understand what gesture you just made.
Sidebar, did anyone else catch the dig at Google Chrome in the Safari announcements? They basically said "Safari is a browser where private mode is actually private" - which is an amazing throwback to this revelation.
By not actually saying anything about ML in those announcements, you instead focus on how things actually make your life easier rather than eating up the current hype.
Hands down, the star of the show is the Apple Calculator App for iPadOS. Why the hell the calculator has never been available on an iPad before has been the subject of many a blog post and article.
But the absolute coolest thing that was announced was the handwriting scratchpad. Simply write your equations out, and the app will do the math for you. It has variables! It can do algebra and trigonometry! It'll add up the items in a list you just wrote down.
Relatedly, that's also how it's doing the "your handwriting is bad and we're gonna make it look less bad but still recognizably like your handwriting".
I was vibing with the keynote for the majority of the presentation. Useful features, minimal risk, finally a calculator. I was a bit disappointed that they DIDN'T FIX STAGE MANAGER, but otherwise it was a good start.
And then Craig walked out to tell us all about ..... Apple Intelligence, immediately triggering my gag reflex.
...but from a company with a better track record on security.
First thing's first, I want to say that Apple did a good job on putting privacy and security first. It's clear that they want to position themselves as the "privacy alternative" to Microsoft, and they've done a reasonable job of that over the years. Not perfect, by any stretch, but reasonable. Keep that in mind as we have a little chat about this.
Apple Intelligence, according to Apple, is a bunch of models running primarily locally on your Apple device provided you've got a strong enough chip (more on that in a second). If the local models determine they can't do a task for you (unknown how it's making that decision, probably going to be on a per-feature basis), it'll farm that out to the cloud, but using "Private cloud compute". That's something Apple just cooked up and has a lot of info around how they plan to do it. They're even opening it up to 3rd party security researchers. Neat!
I'm just a security enthusiast, not a professional (though I do love a good HackFu), so I'm going to leave the "does this do what they say it does" to others. What I will mention is that Apple's reputation for security is miles better than Microsoft, so I suspect the general public is more inclined to believe them when they say something.
It's also going to do Recall-esque things across your entire device, because it has deep access to all the data on your device. It won't be taking screenshots every few seconds because it doesn't have to. It already has deep systems-level access to aggregate everything you're doing. They've been doing this for a while now, for example if you've seen someone send you a picture in iMessage you can also see that same picture showcased for you in Photos. They've been categorizing people, places, and things in your photos for a long while.
Now, because of the deep integration of all of those things, they can semantically search and gobble all of that up at once. Yay!
Look, Apple does have some goodwill left to give it the benefit of "we're not going to pillage this juicy training source and we pinkie promise it's more secure than Microsoft", but this is the same thing.
These local and cloud models will apparently do all sorts of great things:
Make Siri more useful! (maybe)
Summarize your emails!
Summarize and prioritize your boundless notifications!
Summarize your text messages!
Semantic search across your entire device (just like Recall!)
Semantic Search inside of videos! (Possibly getting the subject very wrong)
Write a bedtime story for your child!
Check your Grammar for you! (I'm not sure why you'd use an LLM for that as I've mentioned before)
RIP Grammarly?
Make an Emoji of your friend, without their consent, and send it to them!
Make a custom emoji of whatever you want!
...Generate "art" locally, I guess?
Basically, exactly the same stuff that all the other LLM / Diffusion model companies want you to do smashed together with the idea behind Recall.
Let's take a moment and look at some of the examples they gave
The one that really got me, and I thought was absolutely ridiculous was an example of a student learning about architecture. They'd drawn a fantastic sketch of a building that they were learning about. BUT WAIT! That image is just a sketch. What if we had a machine hallucinate a copy of it? The demo goes on to show how a generative model takes the sketch and makes it into a picture.
Who the hell wants to do that? First off, it was a great sketch, and didn't need to be "enhanced". Second, you're learning about something that presumably...exists. That there are real photos of. Why would you waste the electricity to make a brand new image, that may or may not look like what you wanted when you could...I don't know, find an actual photo of the thing. Wikipedia has one, even! I just... ugh.
It's one thing to want to generate an image of a fictional character that doesn't exist and a whole other thing to want to generate an image of things that absolutely do already exist.
I don't have a lot of energy to talk about this one, but if you thought memoji were weird, at least you had control over that. This time, because Apple Intelligence "knows your friends" you can now make a memoji for them whether they like it or not. Doing...who knows what? Can I type in whatever prompt I want?
I do not like this. Please do not send me any of these. I might block you.
Relatedly, you're going to be able to do contextual diffusion models right there to "really express what you're feeling". I honestly do not understand why anyone would want to do this. I don't get it. Please do not explain it to me. I don't want to know.
Anyhow, those are just two examples of "I don't think they've got a killer use case for this so we're going to guess at what people do with their phones". The real problem is the giant OpenAI shaped elephant in the room.
All the Privacy in the world stops when you send stuff to OpenAI
The other "major announcement" that Apple made at WWDC was their partnership with OpenAI.
Somehow, which wasn't exactly clear during the keynote, if a local model determines that it can't do a thing for you - and the private cloud models can't either, it may prompt you to send your query to OpenAI. This might just be isolated to Siri, or it could be everywhere? I'm not sure.
It's not exactly a "groundbreaking" integration. It's basically the same thing as any other OpenAI API wrapper, but at the OS level (Yikes).
The major problem with this is you may trust Apple not to leak your data everywhere, but you sure as hell shouldn't extend the same trust to OpenAI. Apple assures us that OpenAI isn't retaining that data but OpenAI has been caught lying repeatedly. You cannot trust OpenAI to do what it says it's going to, and shipping an integration to OpenAI right in Apple operating systems is a major breach of trust.
Notably absent from Apple's announcements is "what happens if the thing hallucinates". All we got was a single line at the bottom of a screenshot saying to "Check important info for mistakes". Awesome. We're going to have LLMs summarize everything on your device, and we're not going to mention that it's liable to get those things wrong. Cool.
I expect, especially with locally running models, you're going to get more hallucinations, not less, but Apple seems to think the opposite. Guess we'll find out.
Well, here's a silver lining. I have an iPhone 14 which will not support Apple Intelligence (excellent). So I guess I'm just never going to buy a newer iPhone? My iPad and macbook do support these features so... I'm going to wait until I hear about how much of it I can opt out of before I update to the next version of the OS.
It's possible I'll be sitting on an old OS forever.
Or I'll go live in the woods I guess. I do not want any of this, and it's being foisted upon me because our tech overlords think it's what investors want. The enshittifcation will continue until morale improves.
So, since Microsoft decided to shove AI into everything, destroying what little trust I had left in them in the process, I’ve been giving Linux another go! Now, disclaimers first, I’m still primarily in the Apple ecosystem. All my Cthonic Studios work is done on Macs (and this is partly for software reasons, which I’ll get into in a future post), and I have some Windows Gaming Handhelds (also more on that at the end) but I’m slowly converting some of my tech over.
Today I want to talk a bit about putting a Linux distribution on a Surface Go 1, which is something I wish I’d had the ability to read more about when starting this project, but before we get there I need to do a bit of preamble.
A couple of weeks ago, I put Bazzite on my Framework 13”, and it’s been absolutely stellar. I’ve had zero major issues (and only a small number of minor issues) with that. Games still work! Doing development work still works great thanks to magical containerization! The wifi drivers just work! all in all it just works. It was a wonderful experience.
And all of this is thanks, under the hood, to Fedora.
Bazzite and the other distributions is based on Fedora Atomic Desktops, which are really neat. They’re basically the latest iteration of immutable desktops, which use various techniques to ensure that stuff in user-space remains isolated from the bits that make the computer go “brrrrr” which makes it easier to rollback or make changes to the core OS more safely.
One of the major barriers for me using Linux on the desktop for the longest time has been the propensity of updates to completely bork the system, making it unusable and taking upwards of hours to recover. Fedora Atomic Desktops promises to remove this problem by keeping updates contained and allowing you to boot back into previous versions of the OS after updates. You can even rebase your own version against another version to get yourself back to a known-good state in minutes and pin yourself there until the problem is corrected.
This is amazing. Universal Blue (the people behind Bazzite) also have a handy support document which covers how that functionally works. I’ve done a few updates on the Framework and so far nothing has exploded, so I haven’t had to resort to any of this yet, but just knowing it’s there and how easy it is to roll back is a comfort.
So, I’ve had this Surface Go 1 since it was first released and it’s gone through a series of being wiped about 4 times. Most recently I put Windows 10 back on it and it was…well… painful. The whole thing is super slow, and while the AI nonsense hasn’t made it everywhere, that damned Copilot button did get popped in. I don’t like this.
There’s no reason to get a Surface Go 1 in 2024. I’ve had one sitting around that I’m saving from eWaste and it seemed like a fun project.
So, it was time to try something different. I was so impressed with Bazzite, I wanted to see what it’d take to get Linux running on the Surface.
Here’s where the research started to get a bit concerning.
Running Linux on a Surface device requires a specialized Kernel
Right, so the very first thing you’ll run into when wanting to run Linux on a Surface is that because the hardware is specialized you’ll need a specialized kernel. Fortunately, the folks over at linux-surface have done all of that workand even have a well documented way to get it working. That said, if you start reading the documentation, there are several steps you have to take post-installation to get the kernel installed.
The easiest way, of course, is through the package manager but for some surface devices you’ll need an ethernet port because the Wifi chip isn’t going to work out of the box.
But, I’m lazy. I don’t want to do that. Universal Blue to the rescue.
Universal Blue Images have linux-surface kernels built in
That’s right kids, Bazzite and its peer systems (Bluefin, Aurora, uCore) have an image you can download which includes the linux-surface kernel in it.
Since I figured the Surface Go wasn’t going to be giving me a lot of gaming mileage in 2024, I went with Bluefin with the developer tools not preinstalled.
Sidebar, near as I can tell Bluefin and Aurora are the same except for Aurora uses KDE and Bluefin uses Gnome as the desktop manager.
This turned out to work great. I had zero problems wiping the entire drive, installing Bluefin, and then running it, though I did run into a couple of issues.
This was an extremely straightforward process, so I’m just going to use a numbered list:
⚠️ Now, you might notice that below I don’t re-enable Secure Boot. This is because I didn’t update the BIOS before starting this process and older versions of the UEFI menu do not allow you to boot 3rd party systems with secure boot. I’ve not tried fixing this yet via linux, but I will update this post if I get around to it. So if you’re coming behind me, update your BIOS to the latest before doing this using Microsoft’s update tools.
Download the surface image from the Bluefin site. Follow the prompts and they’ll give you the right options.
This thing isn't going to win any speed contests any time soon. Earlier, I was watching a youtube video while trying to multitask on it to see what it'd do, and while it behaved admirably given its aging hardware, it still stuttered when displaying the second display at 2k, playing video, opening discord, and trying to open LibreOffice.
Once everything was running, it wasn't a bad experience (certainly better than windows), but it was still kinda sluggish.
The other thing that I had thought / hoped we'd solved is the blurry bits on a high DPI display with Electron / Chromium apps. The tl;dr here is you have to enable the Ozone settings and set it to use ozone as the renderer in each of these apps flags: --enable-features=UseOzonePlatform --ozone-platform=wayland which will fix the display to work properly.
One final bit: you need to remember to suspend it manually if you don't want the battery to drain while you're not using it. I suspended it and left it overnight (for around 10 hours before I checked) and it'd drained about 10% in suspend, which was pretty good all things considered.
But yeah, otherwise everything worked pretty well!
So, I also have a Aya Neo Air which I’m barely using and guess what “mostly works” on it? ChimeraOS. So, I’m going to tinker around with getting that installed and working on it in the nearish future and see how it goes. I’m not 100% sure I want to do this since I’ll lose some of the Aya Neo niceness (for example, the TDP switcher is broken in Chimera so you have to use a different app).
I can’t do this on the Ally as no distribution will ever properly work with that proprietary connector for the XG Mobile so I’m going to have to keep playing cat-and-mouse with Windows on that one, but…yeah.
Anyhow! Hopefully I’ll get to report back with good news next time.
Right, so here we are again, just another step in my journey to find a way to opt out of all the “shove generative AI into everything” trend in my personal life. In my last post on the Apple Intelligence announcement, I ended on a note of “well, I guess I’ll just not upgrade”. That’s a viable strategy for a while (which I intend to make use of for as long as I can), but in the long term it might not be viable.
Look, I’m not totally opposed to running an LLM or something on device, but I want it to be on my terms, not baked into every interaction with the operating system. Apple seems best poised to allow that kind of behavior (which is funny given their track record on customizations), while Google and Microsoft are hell bent on shoving this everywhere in search of the next big thing.
Thus, I spent a week running an experiment running one of the many projects based on the Android Open Source Project (AOSP), the open source part of the Android project sans the Google Extras. I figure the LLM stuff won’t make it into the open source side of stuff maybe ever since Google sees it as a moneymaker (or do they?), so it seems like a reasonably safe bet for a while.
In order to simulate what my life would be like in a world where I try to get away from the big players while still holding a smart phone (a dumbphone or Lightphone are always options), I set some rules for myself.
No signing into Google services on the phone. They shall not touch the datas.
No signing into Apple services either. It’s not as big a problem, but I do use Apple Music all the time.
Stay as close to the OS’s preferences as possible.
That’s pretty much it, but I did a bit of a bonus goal while I was doing this. I paired a CMF Watch Pro and used the CMF Buds Pro as my daily drivers for the same time period. I wanted to go with a bit of a “budget premium” experience to challenge myself on the “do I really need the best stuff”
As an aside, my primary watch is an Apple Watch 6 and I see no reason to upgrade.
There are a lot of different flavors of AOSP projects out there for various needs. Lineage OS is probably the most common one out there, and Graphene OS is the extreme privacy / security focused version, but I went with /e/OS because I was already familiar with it and it offers a very interesting sync capability (which I’ll get to at the end of this post).
/e/OS is itself a Lineage fork, by the by
Now, I could have gone off the board to a Linux based phone distro (and I may give that a go in the future) but that’s a big jump I didn’t want to take - and I wanted to try to preserve the “app ecosystem” that I’m used to. Which is a big advantage of /e/OS: it ships with MicroG (which they maintain) and an app store that can pull APKs from the Google Play store anonymously (thus fulfilling rule #1 but still taking advantage of the Play store ecosystem). Jumping to only using progressive web apps (PWAs) and open source apps was a bit too far of a stretch for my daily driving.
Now that I’d picked an OS, I needed to pick a phone that would both be compatible and ideally wouldn’t create more eWaste in the process. My original plan had been to use an old Galaxy Note 10 that we had lying around, but unfortunately Samsung US phones have locked bootloaders that are a pain to unlock. So, I went on Backmarket and found a Pixel 6 Pro Unlocked, and in good condition. I did this for both price and compatibility reasons, before you set out on this endeavor yourself, you’ll want to read the supported device list for your given OS carefully.
Unlocked from Google is an important distinction here. The ones the Carriers sell may not be able to unlock the bootloader as well, leaving you stuck with stock android.
The phone arrived safely and was in pretty good condition. There were a few scuffs, but nothing a thin screen protector couldn’t hide (sparing me the madness of noticing it all the time).
/e/OS also has an “Easy installer” that supports some newer devices, which is very fancy and easy. Unfortunately, a Pixel 6 Pro is not one of the supported devices.
Okay, so this part is very straightforward, but requires a few steps and you need a separate computer to do it. That guide is here. At a high level, the process is:
Download 2 files from the /e/OS site
Ensure Android SDK tools are installed on your computer.
Use adb / fastboot to reboot into recovery mode.
Use fastboot to unlock the bootloader.
Flash the files from step 1 onto the phone.
Reboot and enjoy your new OS.
Okay, we need to take a quick second and talk about unlocking the bootloader for those who are unfamiliar. The bootloader tells your phone how to load Android, and it is locked to an official version of Android so that you can be sure that the OS running on your phone is what you and the manufacturer expect it to be. It’s one of the things that prevent hackers with physical access to the device from doing nefarious things.
Now, unlocking the bootloader is both what allows you to flash a different OS onto the device, but it also breaks that integrity guarantee, meaning if a threat actor grabs your phone and has a few minutes, they can do some shenanigans like pull all the data off of the phone.
Some devices support relocking the bootloader. The Pixel 6 Pro is not one of those devices. This can still be fiddly even if it is supported.
/e/OS takes a defensive step against this by encrypting the data at rest, encrypted with your password (or pin) so that if that were to happen, at least it’s behind an encryption wall. Now, they could also potentially load malware onto it, which then also hijacks your password and conceivably sends it somewhere, but those are the risks we take.
At its core, /e/OS is just the stock Android 13 experience without the google services built in. Instead, it ships with MicroG, which is an open source implementation of most of the Google APIs.
What this means is that most Android apps, even the ones that rely on Google Play services will still work. (SafetyNet also works in some contexts, though I don’t have any apps that are using it). You can control / enable / disable MicroG at your leisure, but it is necessary for push notifications to work. In particular, Push notifications must still register with Google services because that’s just how push notifications have to work - there are no alternative push servers. There are some apps that allow polling for notifications, but if you want them in realtime, this is your only option (that I am aware of). These are still anonymous as documented here.
The default Launcher (Bliss) is a lot like older iOS before the app drawer existed - namely, there is no app drawer. All installed apps just appear on the home screen. Also, you can’t place widgets anywhere except the leftmost screen. I’m not the biggest fan of this experience, but I stuck with it for this experiment. If I were to do this long term, I’m liable to install an alternative launcher (I like Nova).
A stock Android phone without installing apps will not be very useful unless you’re going for a minimalist kind of thing, but that’s not me, I want apps. You do have the option of only installing open source apps, but that’s also not going to get me to a fully functional app (Look, I use Discord a lot).
App Lounge has a very handy feature so that I would not break my first rule: You can use an anonymous Google account to download apps from the Play Store. This requires you to additionally trust the /e/foundation to not tamper with the apps as they’re being installed, but the app is open sourced so it can be audited and it wouldn’t behoove the e foundation to slip in some back doors. Anyway, using one of any number of anonymous accounts they maintain, you can essentially side load apps from the official play store, which means I can install Discord without too much trouble.
The other neat feature they’ve baked in is the “Advanced Privacy” which essentially blocks ad trackers at the OS level and gives you a handy report on every tracker it’s blocked and which app the request originated from. This includes stuff like the usual Firebase analytics, all the way down to some less common ones like Qualtrics.
I’m pretty sure they’re doing this purely on the domain of the request and using a block list to make the determination, which means some stuff is probably slipping by, but it’s pretty fun to see that DoorDash is extremely leaky.
Likewise, the Aurora store gives most apps a privacy score out of 10. You’ll see a lot of them with a 0/10 on the privacy list, because of all the tracking.
So one of the other really neat things about /e/OS that I wanted to mention is their cloud service, which they’ve got an integration directly in the OS which allows you to sync files, notes, contacts, emails and the like as you would if you were heavily in this ecosystem. Murena.io hosts this cloud service, which gives you 1 GB of storage for free and charges a reasonable fee for upgrades.
But we’re not in this to simply trade one cloud provider for another, oh no. The coolest part about the cloud software is that it’s essentially a specialized fork of Nextcloud, and it’s open sourced. That means, theoretically, you can run the whole set of cloud services on a server you control, deeply integrated with your mobile operating system. That’s pretty neat.
Now, you can already do this with vanilla Nextcloud and the various Nextcloud apps, but you’ll lack the built in integration. It’s not a big hassle to just use Nextcloud, but it is really appealing that built-in integration supports private servers.
The other thing that is cool is that murena.ioalso just works as a Nextcloud server, so you can do things like use the Nextcloud Feeds app to sync up with RSS feeds you put up in murena.io. Or use the Nextcloud files app to sync your files if you really want to. Lots of flexibility there to host or not host what you want.
Now that the experiment is over and I’m back in the corporate embrace of Apple, what did I like about the experience?
Overall, I was really impressed at how smoothly everything went… for the most part. I could install all the apps I needed, and the PWA support for other major apps (like Starbucks) meant I didn’t need to install as many apps as I have before on other Android phones.
I was also blissfully free of the “TRY GEMINI!” pop-ups that have started appearing on other Android phones (like my Motorola G5 Power) or whatever Samsung is calling theirs (which also just appeared on my wife’s Galaxy S22).
I was concerned that I wouldn’t be able to install an eSIM and get it working, but I was also pleasantly surprised that worked without any issues as well.
The only major issue I ran into whilst doing this experiment is that I make heavy use of Apple pay on the Apple watch, specifically to store my transit card. Tapping and getting on transit is an essential part of my day, which was sorely lacking on the /e/OS build. Payments are probably never going to work on the phone directly (because of how payment industry infrastructure works and requires direct partnerships).
There are some workarounds. I decided to see if I could get my old Galaxy Watch Active 2 to pair and verify a card via Samsung Pay on the watch, and I’m happy to report that after some wrangling, I got it working. The only major hurdle is that I had to install the Edge browser and make it the default so that Samsung would let me log into the Galaxy Wear app.
Now, this is a Tizen based watch, not a WearOS watch, so I have no idea how a WearOS watch is going to function, but reports on the forums don’t look very promising. If I wind up trying it out, I’ll write a follow up post.
The forums have had some success with Garmin Watch / Garmin Pay, but the banks that Garmin Pay supports are pretty limited in the US.
Either way, I got the Watch Active 2 to verify a card, and I was able to tap and pay at a Petco shortly after verifying it. So, uh, success!
Overall, I think this was a pretty successful experiment, and should I be unhappy with my ability to disable OpenAI integration in iOS 18 I can at least switch my phone if I need to - but given that I can just stay on 17 for an indefinite period of time I’m unlikely to make the jump just yet.
I'll update this post when I've got the review of the CMF watch up with a link to it!
Last week, I did an experiment with /e/OS on a Pixel 6 Pro and in the process I also wanted to use some CMF accessories with it. That part was driven by how impressed I was with the CMF Buds Pro (have a look at my headphones page for more) at their price point so I thought the watch might also be great.
Sidebar, apparently there’s also a CMF phone en route.
The CMF Watch Pro (Amazon affiliate link) is a $70 “smart” watch with an incredible battery life and basic biometrics. That price is just a hair more than some of the other Chinese brands (TOZO, for example, makes a comparable watch a touch cheaper), and it’s a bit under something like a Ticwatch. It’s well under the cost of a new Apple / Samsung / Pixel Watch as well.
Some facts about this thing at a glance:
10+ Day Battery Life (I wore it for close to 11 days before I charged it at 10%, though I wasn’t using all the continuous monitoring).
IP68 Water/Dust Rating
Bluetooth 5.3
Biometrics: Heart Rate, “Stress”, Blood Oxygen
GPS?
Swappable Watch Band (which I wore too tightly and got a small abrasion wound from)
Use the watch as a microphone and speaker for phone calls.
I definitely did not do this. I hate phone calls.
No NFC, so no payments (unlikely at this price point)
The design and finish of the watch is really nice, it looks good on the wrist and it’s generally comfortable unless you’re me and you pull the band too tight (or have a propensity to put your face on your arm during sleep). The size of the watch face is great.
Connecting the watch is pretty standard compared to other watches. There’s a companion app you need to install on both Android and iOS which needs to run in the background for many of the functions. The app lets you download new watch faces, change settings, and pretty much what you’d expect.
I’ve read about many people having issues keeping the watch connected, but I had no issue with that. I never noticed the connection drop the entire time I was using it.
I liked a lot of the experience, but there were also many weird minor issues that make me appreciate the Apple Watch more.
Overall, there were a lot of good points to the watch when comparing it to something outside of its price category (an Apple Watch series 6, which you can get refurbished for around $120), not least of which was the battery life. It is super annoying that I have to charge my Apple Watch every night before I go to bed. Not having to charge a watch for over a week is outstanding.
Biometrics seemed to work very well compared to my normal experience on the Series 6: My resting heart rate is measuring within 5 bpm on the two platforms, as do longer walks. The Blood Oxygen also seems to measure the same (though accuracy of that overall can be a little hard to measure - still good in a pinch). I don’t know how to qualitatively measure what “stress” means to the CMF watch, but apparently I’m not too stressed about.
All the other basic features also work as you’d expect. You can:
Set alarms from the watch and they go off at the right time.
Set timers!
See the weather (but only for today, and it only updates every 3 hours).
Do some exercises, which use the GPS to track the activity when you’re outdoors.
Control your music player.
See notifications!
As MKBHD mentions in his Youtube Review, it’s essentially just a basic bluetooth extension with your phone. It’s a fine watch, and I wouldn’t really mind wearing it around for a while, though there are some things I’d miss. We’ll get to that in a second. First let’s talk about the problems I had.
The biggest issue by far is the utter lack of multitasking. For example, if you start a workout, you can no longer control your music player from the watch. Same deal with the timer. You must keep the timer app running, otherwise it’ll stop the timer. It’s a major problem for doing any of those things on the watch.
Like, if you’re on a run, I guess you can use the touch controls on your earbuds, but I frequently use the watch to adjust stuff when I’m on a regular walk.
Speaking of workouts, I could never get it to find the GPS before I started the workout. Every time I just had to skip the connection and continue. I do think the GPS did eventually connect, because it showed an accurate path when I reviewed the workout later.
Another thing that was “fine” but was pretty annoying was the lack of auto brightness. If I had the watch at the lowest brightness, and then went out into the sun, getting the brightness to the place where I could properly see the screen was difficult.
The last “major” thing I encountered was one of the things that makes the watch look really nice: the sharp corners. You see, I tend to put my head on my hand when I’m sleeping, and I kept essentially stabbing myself in the face with the edges while I was asleep. That’s not something that happens with the rounded corners on the Apple Watch.
So let’s talk about some things that I missed which made me appreciate the Apple Watch after running through this experiment.
At the price of the CMF Watch Pro, I don’t expect it to have these things, but I definitely notice stuff I took for granted on more expensive smart watches.
So besides the fact that multitasking is kind of essential for me when I want to work out and listen to music, or set a timer, there were a couple of things that I missed out on.
Tap-to-pay was probably the thing that was the biggest “loss” of not using my Apple Watch. I have my transit card connected to Apple Pay, so in order to get on the bus or take a train, I would need to either tap a credit card, or go buy a physical transit card. Not a huge deal, but enough that I missed it (to the point where I brought the Apple watch with me to avoid having to buy a plastic card).
The other thing was the lack of automatic activity tracking. I regularly forget to start a workout, but the Apple Watch has my back and will alert me to start the activity. Sometimes it nags me several times in a row. This leads to tracking more workouts properly. The CMF watch does not do this so you have to be diligent to start it if you want to track it in real time / with GPS.
… And auto brightness. Definitely auto brightness.
Overall, I was pleasantly surprised with the “premium basic” watch experience while also testing out /e/OS, and also pleasantly surprised that it connected just fine and had no issues when loading the app on a de-googled phone.
If you’re just in the market for something that’s very basic, and can live with the no-multitasking, I think the CMF Watch Pro is a great option for the price.
I had a fair amount of fun trying this out, so I may try out some other low-price watches in the future, we’ll see.
tl;dr I’m no longer recommending Proton services to anyone and have moved off to other services.
Right, so up until recently I was a happy Proton customer at the annual unlimited tier. They were missing some convenience features and the integration of a document editor into the Drive product was pretty great.
That is, until they decided to shove an LLM into their core product and upend their security model and break some trust by the way they rolled it out. Let’s take a quick look at their timeline / speedrun of adding LLM features (and Crypto wallet, but we’ll get there in a sec).
So I took this survey, and I’m now kicking myself for not screenshotting the questions, because I have a lot to say about shitty survey design.
I’m going to do some conjecture and speculation here, but I think that the survey was designed when they already had the Scribe product already well into development and that the questions were designed to make it seem like the product they were already developing was by popular demand. Like, you don’t develop a “privacy preserving” (it’s not) LLM in 1.5 months. They were already building this thing.
Let’s talk about those results. They provide this graph in their survey results post:
My recollection of this question is that it was a multiple-choice, but not stack-ranked question. I’m not sure if that’s how it actually was, just how I remember it.
Regardless, I want to point out 2 things:
The LLM answer in there doesn’t actually mention an LLM. It mentions a “writing assistant”. There are tons of things that do not use Large Language Models to do writing assistants, like checking grammar and spelling. The way they worded that answer was extremely misleadging.
Only 29% of respondents said they wanted it.
So let’s move on to the second point they try to make in this survey that absolutely does not say what they say it does.
And here’s their analysis of that data:
Generative AI is one of the most significant developments in recent history, and it is supposed to lead to incredible gains in productivity. As more and more AI assistants come online, we asked the Proton community what they thought of these tools. Around 42% of respondents use an AI service regularly (at least once a month), and another 18% have never tried AI but are interested in it.
I just. sigh.
The survey asked do you use Generative AI. It doesn’t ask why. It doesn’t ask if you find it useful. It doesn’t ask if you WANT IT IN YOUR FUCKING EMAIL CLIENT. This tells you nothing!
“At least once a month” is not very much Generative AI usage.
That’s still under half of your user base!
This question is poorly designed. I can’t tell if it’s poorly designed as an excuse to interpret the results the way Proton apparently wanted to, or if it was a genuine “surveys are hard to design” take, but asking “do you use Generative AI” without also asking “Do you use Generative AI for spicy roleplay” and “do you want us to put an LLM into your Email client” is ridiculous.
So, I don’t think this survey is a killer “Our users want this” result.
In their announcement post they make the following assertion:
In our 2024 community survey, more than 75% of Proton’s business users said they are interested in generative AI tools, but most were also concerned about a lack of data protections. Scribe was designed to be a secure alternative.
Right. Okay, I don’t think that’s what those survey results actually say (since you didn’t ask “do you want a secure alternative if we build one”).
When the backlash to this feature started over on Mastodon, they had the following response:
This excuse is flatly ridiculous. “We thought ‘hey they’re gonna do it anyway, let’s do it so they can be safe’”, is what that amounts to. That’s not a smart way to roll out features - and I don’t actually buy it.
Proton’s descriptions of Scribe are vague and waffly about their threat model. Your prompt — that is, the email you’re writing — is kept in plain text on their server, unlike emails you’ve sent or received, which are secure at rest. Proton promises they don’t log the prompts — but services like Apple, which many Proton users were trying to get away from, make only the same level of promise.
Proton then goes on to point out that the Model can run locally…. but only on Chrome, and only on systems with high enough system specifications. They went on to respond to this post with the following rebuttal on Mastodon:
I want to break down some of these things.
The feature is not “opt-in” if you’re on affected plans. It shows you this dialog:
Notice how that dialog doesn’t have a “no I don’t want this” option. To turn it off, you have to go into the settings. That’s an opt-out feature. Not opt-in.
The second thing is that there’s no such thing as an “Open source” model. The weights may be open, but Mistral has been super cagey about where they got the training data (also known as, they got it the same place all the other companies did - the internet, without permission).
Finally, if you or someone you’re chatting with decides to use the “zero logs server” the text is sent to them in the clear…. which I think very much does break their zero-knowledge model.
You’ve totally broken your privacy model for your users, willfully. For an LLM.
Ugh.
But that’s not the most ridiculous thing about this whole saga.
If Proton was taking privacy seriously they’d have used Monero or Zcash — two cryptos that use zero-knowledge proofs to make transactions untraceable through the blockchain data trail. At least these have a use case, even if it’s buying Russian research chemicals off the darknets.
Yeah, exactly that. Bitcoin isn’t private, and no amount of you providing a non-custodial wallet is going to change that.
Here’s the security model. This is a reasonable attempt at the functionality, but it doesn’t make the basic idea any less dumb. Also, they recommend you use a bitcoin mixer so the Feds can bust you for money laundering too when they match you to your bitcoin address.
I really wish I knew. The timeline makes it clear to me that they had several potentially very unpopular features already in development and then timed the release with their developer survey. I suspect they were hoping to spin the results as a “you asked for it and guess what we delivered in record time!”.
The spaces I hang around in are very skeptical of both Generative AI and Crypto, and I think that Proton’s core individual customer is too. It feels like they’re speedrunning a “alienate our core customer base” but I honestly don’t know what they’re doing here.
It’s possible that their business users really do want this thing and have been asking for it for a long time. It’s also possible that the people running the show are adding features for a future investment or a sale. That doesn’t really jive with moving to a non-profit.
It’s also possible that they’ve always loved LLMs and Crypto and just happy to shove it into everything.
But, it doesn’t functionally matter for me. They’ve broken my trust, and that was the primary currency and reason I’d be willing to shovel money towards them. That takes a while to build. It takes an instant to destroy.


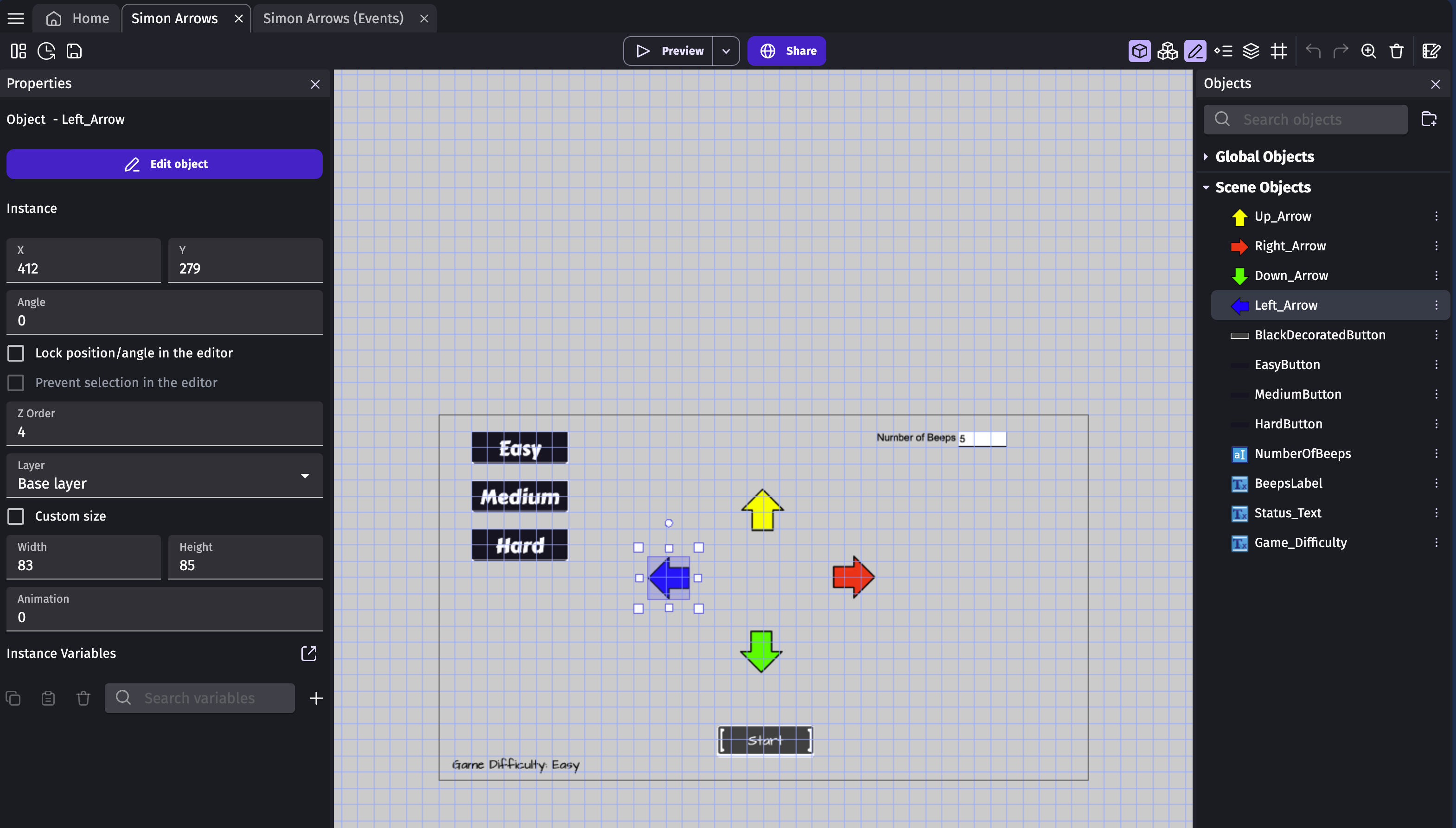
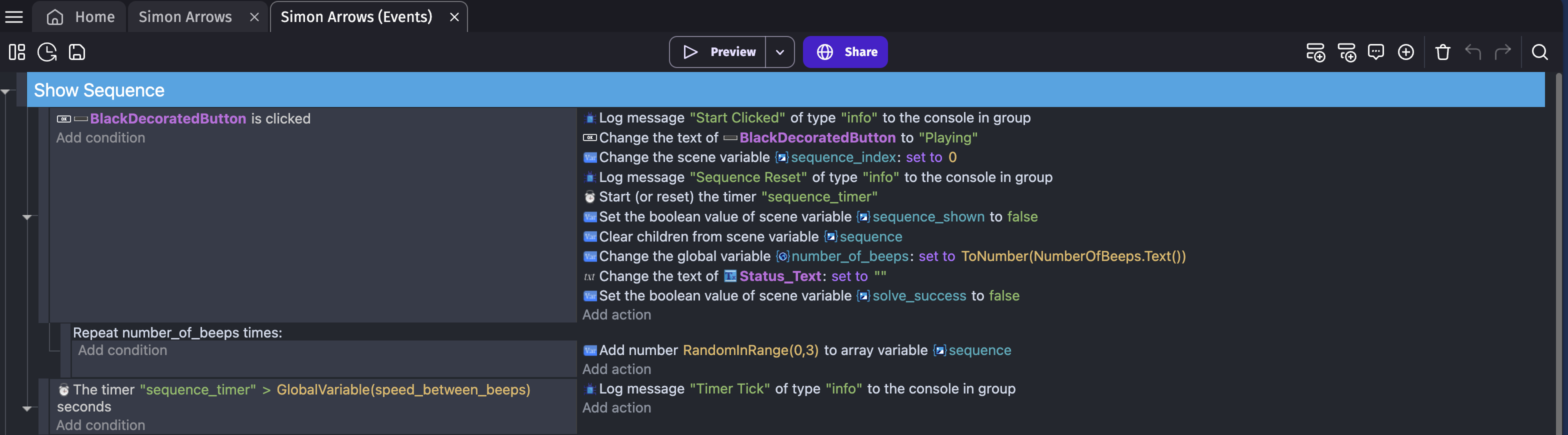


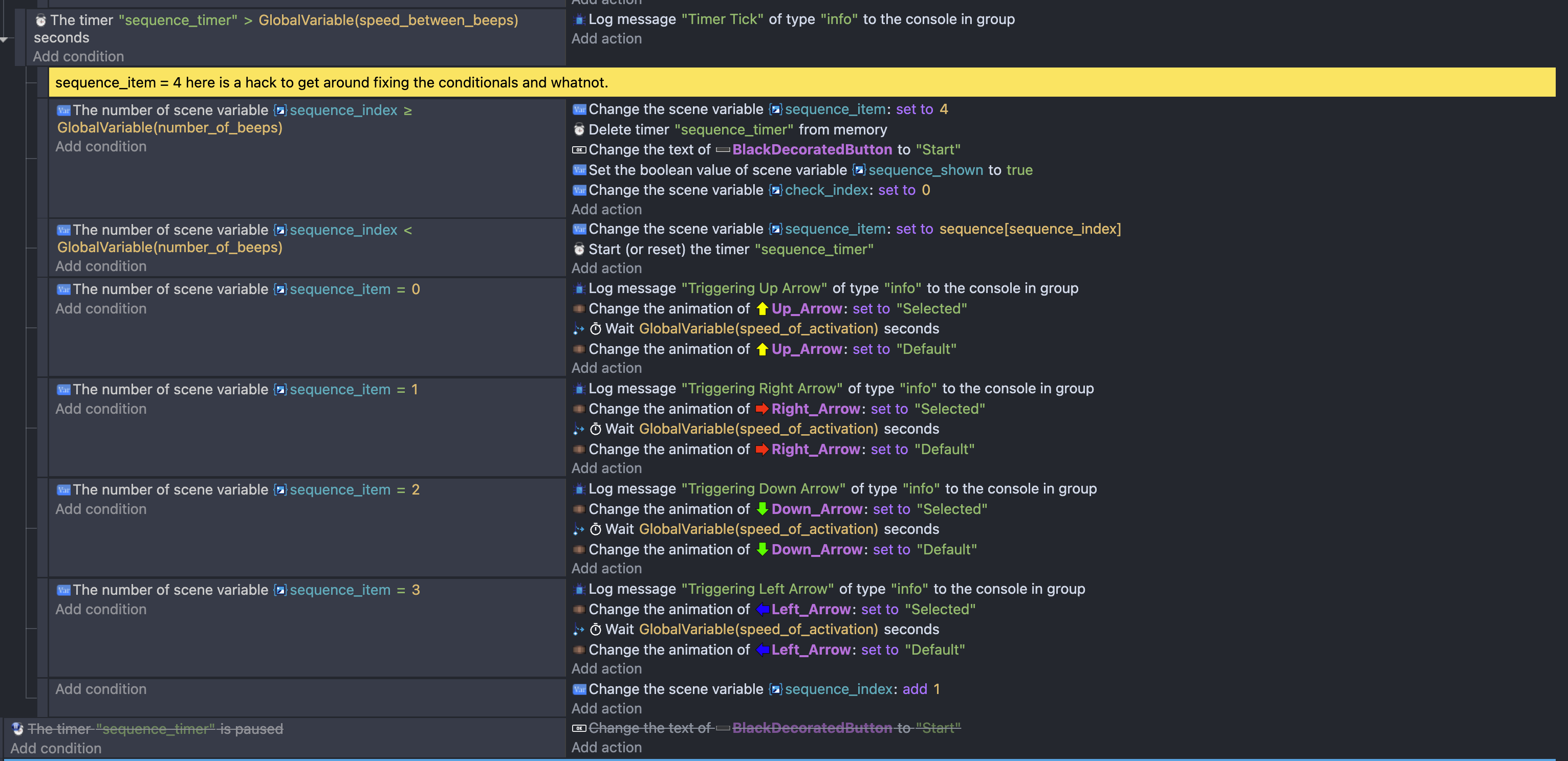














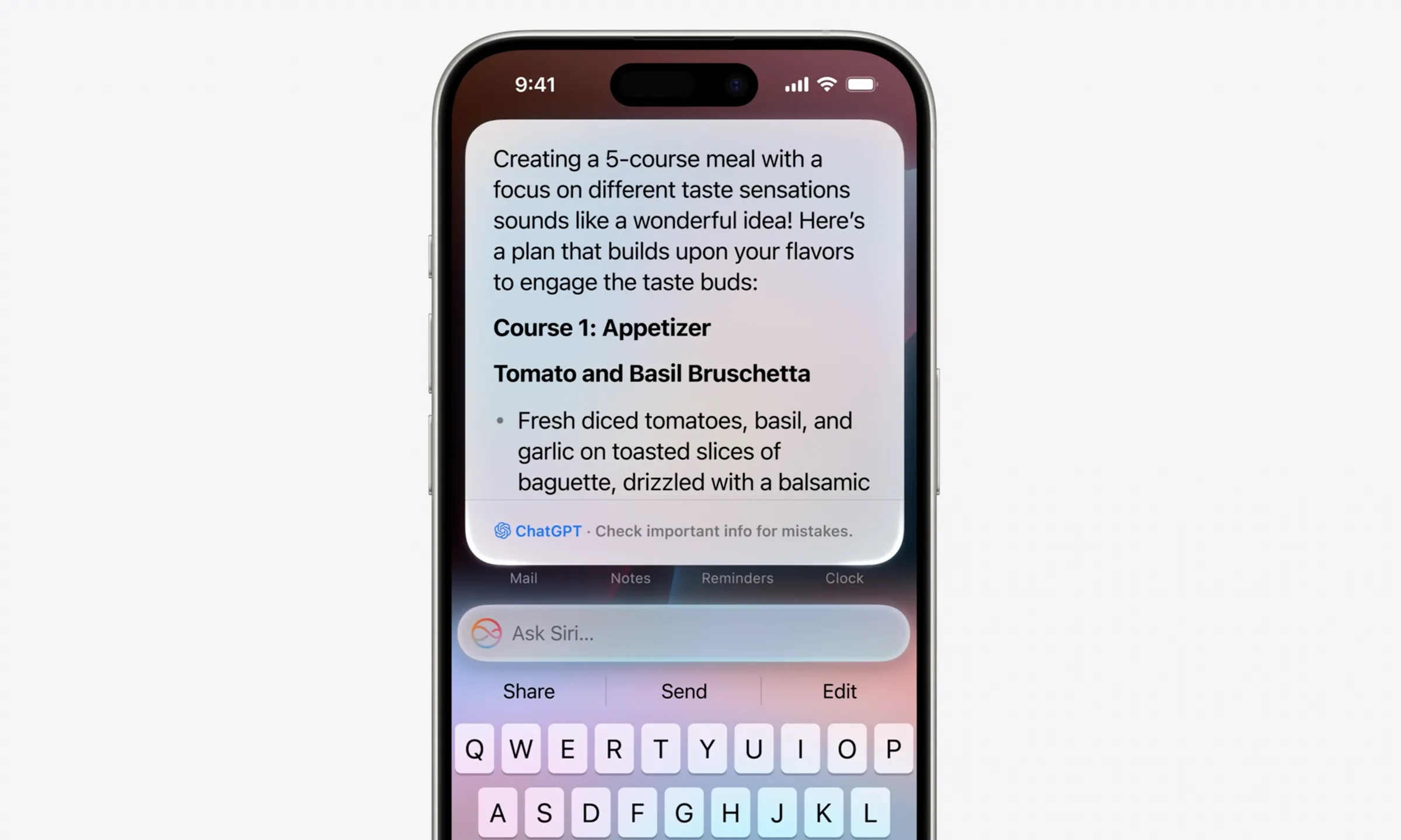



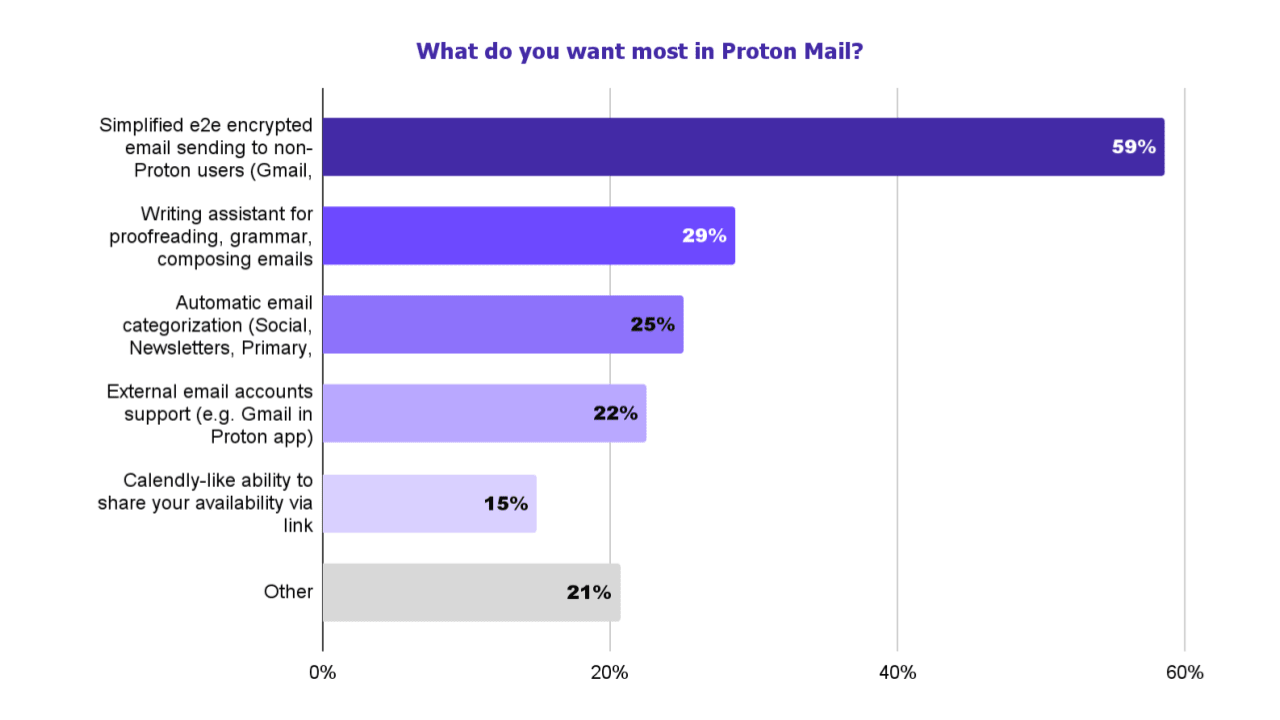
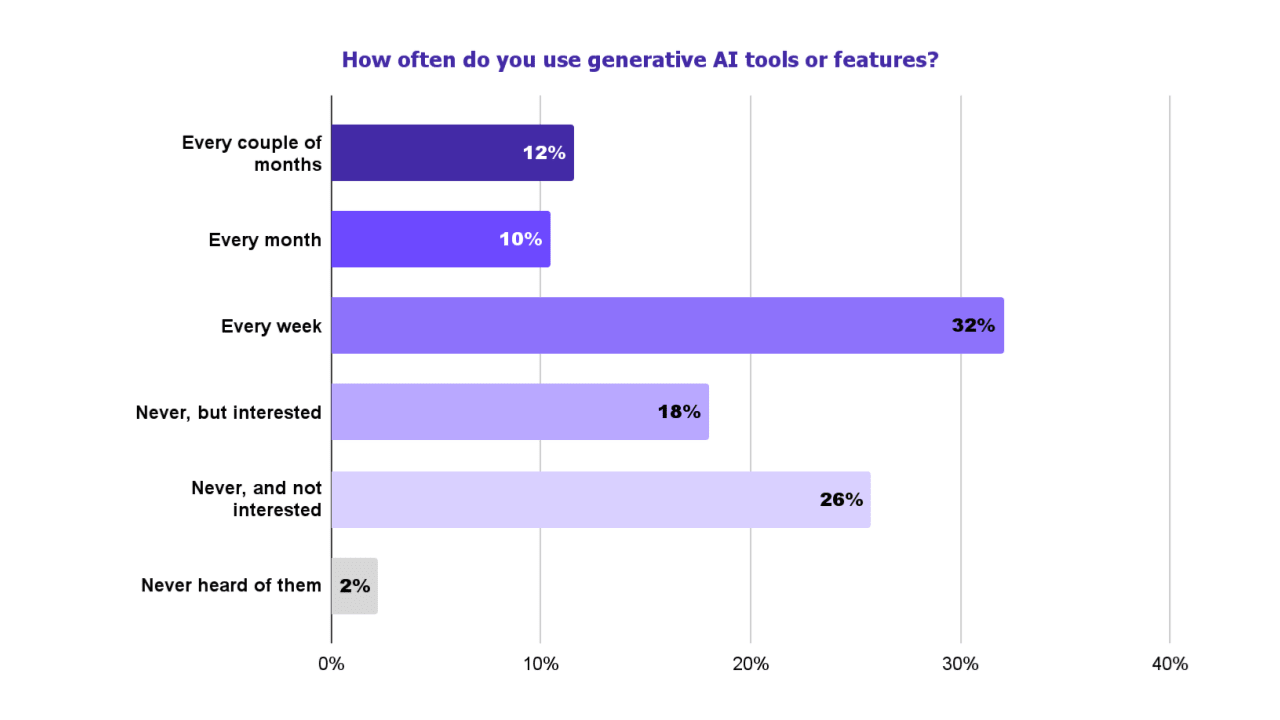
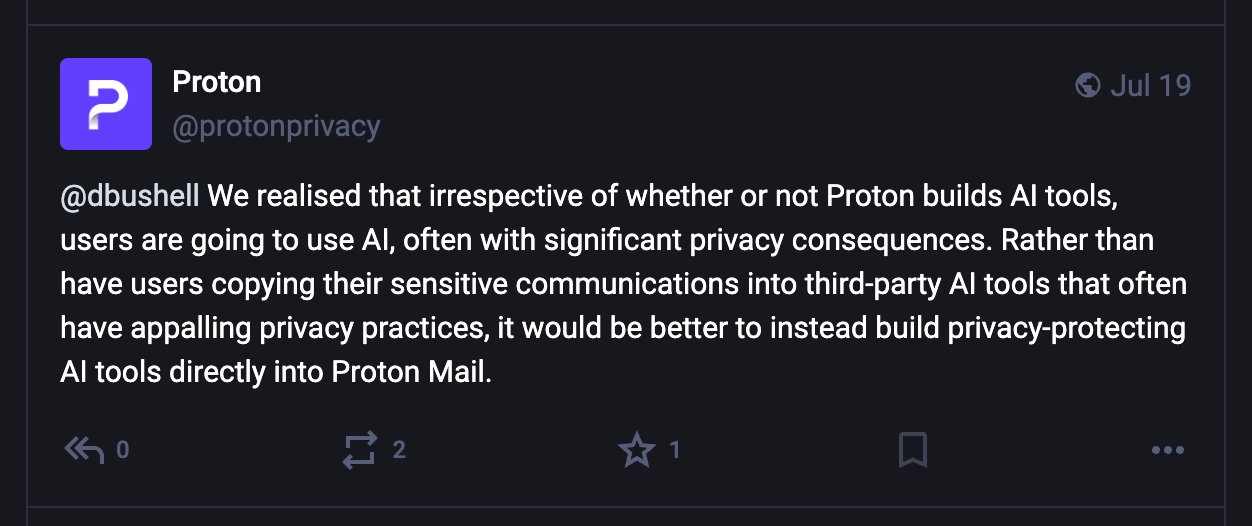
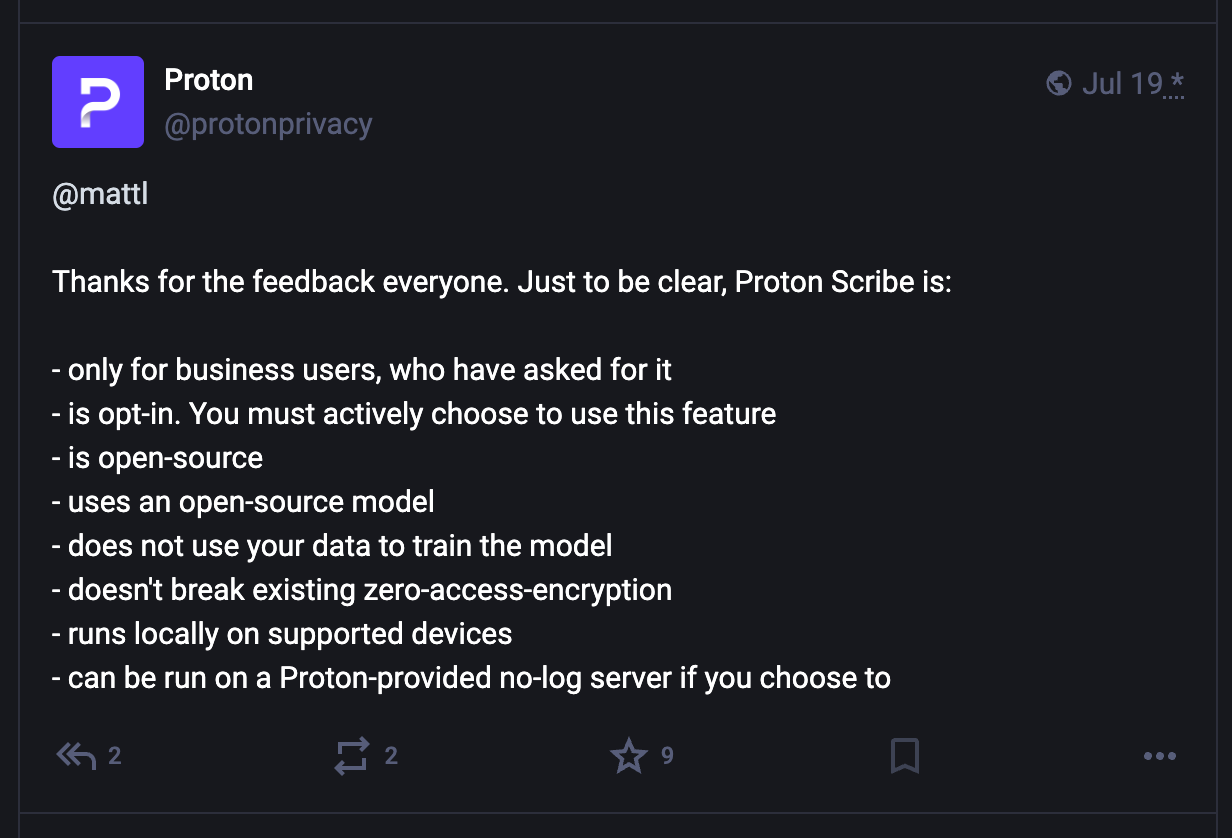
{kind=link}